Lo primero, feliz año a todos (no me da la gana de poner todas y todes), y espero que este año sea mejor que el pasado.
Hoy voy a hablar un poco de la “cocina” electoral en los barómetros de opinión, pero de forma muy simplificada.
Una de las primeras cosas que se hacía era comparar el recuerdo de voto declarado en la encuesta con el resultado real de las elecciones a las que hacía referencia.
Cuándo no coinciden una de las cosas que se hacían era imputar el recuerdo de voto para aquellos que no contestaron a la pregunta. Esto se hacía utilizando variables de la encuesta, típicamente variables de autoposición idelógica y similares.
Una vez imputado el recuerdo de voto se comparaba de nuevo con el resultado real de las elecciones y si variaba se recurría a la ponderación por el recuerdo de voto real. Esto es, se estimaban unos pesos de forma que la distribución del recuerdo de voto en la encuesta fuera lo más similar posible a los resultados reales.
Esta “reponderación” corre el riesgo de descalibrar la encuesta en otras variables, tales como sexo y edad, por poner un ejemplo. La solución podría ser postestratificar la muestra, pero para eso deberíamos saber los valores poblaciones en cada combinación de sexo, edad (posiblemente agrupada) y recuerdo de voto. Es decir, tener la distribución conjunta, lo cual implica tener por ejemplo todas las combinaciones de edad y partido al que votó en la muestra y también saber la distribución poblacional (en las elecciones consideradas). Evidentemente no siempre es posible tener tanta información, por lo que se opta por al menos ajustar las distribuciones marginales.
Para obtener esos pasos se utiliza un procedimiento iterativo llamado raking
Para ver como se haría esa parte de la “cocina” (lo de imputar los nulos en recuerdo de voto usando un modelo no lo voy a hacer), utilizando la librería survey de Thomas Lumley.
Fuentes de datos.
Resultados electorales oficiales utilizando la fantástica librería
infoelectoralPadrón oficial de habitantes a 1 de Enero de 2020.
Obtención datos
Encuesta CIS.
library(tidyverse)## ── Attaching packages ────────────────────────────────── tidyverse 1.3.1.9000 ──## ✓ ggplot2 3.3.5 ✓ purrr 0.3.4
## ✓ tibble 3.1.6 ✓ dplyr 1.0.7
## ✓ tidyr 1.1.4 ✓ stringr 1.4.0
## ✓ readr 2.1.1 ✓ forcats 0.5.1## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(infoelectoral)
library(magrittr) # ##
## Attaching package: 'magrittr'## The following object is masked from 'package:purrr':
##
## set_names## The following object is masked from 'package:tidyr':
##
## extractlibrary(patchwork) #
df <- haven::read_sav("/home/jose/Rstudio_projects/raking_ejemplo/MD3340/3340.sav")
df %<>% ## change in place
rename_all(tolower)
# Convierto a factor algunas variables para que pillen el label que
# viene del fichero de spss.
df <- df %>%
mutate(across(.cols = c(ccaa, sexo, recuerdo, recuvotogr,
intenciongalter, intenciong, intenciongr,
intenciongalterr), .fns = as_factor))
# categorizmaos la edad
df <- df %>%
mutate(
gedad =
case_when(
edad >= 100 ~ "100 años y más",
edad >= 18 & edad <= 24 ~ "18-24 años",
edad >= 25 & edad <= 29 ~ "25-29 años",
edad >= 30 & edad <= 34 ~ "30-34 años",
edad >= 35 & edad <= 39 ~ "35-39 años",
edad >= 40 & edad <= 44 ~ "40-44 años",
edad >= 45 & edad <= 49 ~ "45-49 años",
edad >= 50 & edad <= 54 ~ "50-54 años",
edad >= 55 & edad <= 59 ~ "55-59 años",
edad >= 60 & edad <= 64 ~ "60-64 años",
edad >= 65 & edad <= 69 ~ "65-69 años",
edad >= 70 & edad <= 74 ~ "70-74 años",
edad >= 75 & edad <= 79 ~ "75-79 años",
edad >= 80 & edad <= 84 ~ "80-84 años",
edad >= 85 & edad <= 89 ~ "85-89 años",
edad >= 90 & edad <= 94 ~ "90-94 años",
edad >= 95 & edad <= 99 ~ "95-99 años",
)
)
df$gedad <- as.factor(df$gedad)
head(df)## # A tibble: 6 × 254
## estudio registro cues tipo_tel ccaa prov mun tamuni entrev
## <dbl+lbl> <dbl> <dbl> <dbl+lbl> <fct> <dbl+lb> <dbl+lbl> <dbl+l> <dbl+l>
## 1 3340 [3340] 3982 1 2 [Móvil] Andal… 4 [Alme… 0 [Mun.… 1 [Men… 0 [Ano…
## 2 3340 [3340] 8979 2 2 [Móvil] Andal… 4 [Alme… 0 [Mun.… 3 [10.… 0 [Ano…
## 3 3340 [3340] 11104 3 2 [Móvil] Andal… 4 [Alme… 0 [Mun.… 3 [10.… 0 [Ano…
## 4 3340 [3340] 4205 4 2 [Móvil] Andal… 4 [Alme… 0 [Mun.… 3 [10.… 0 [Ano…
## 5 3340 [3340] 1191 5 1 [Fijo] Andal… 4 [Alme… 13 [Alme… 5 [100… 0 [Ano…
## 6 3340 [3340] 1203 6 2 [Móvil] Andal… 4 [Alme… 13 [Alme… 5 [100… 0 [Ano…
## # … with 245 more variables: capital <dbl+lbl>, sexo <fct>, edad <dbl+lbl>,
## # p0 <dbl+lbl>, p1 <dbl+lbl>, p2 <dbl+lbl>, p3 <dbl+lbl>, p3_1_1 <dbl+lbl>,
## # p3_1_2 <dbl+lbl>, p3_1_3 <dbl+lbl>, p3_1_4 <dbl+lbl>, p3_1_5 <dbl+lbl>,
## # p3_1_6 <dbl+lbl>, p4 <dbl+lbl>, sersanientre <dbl+lbl>, p4anno <dbl+lbl>,
## # p4mes <dbl+lbl>, p4a0_1_20 <dbl+lbl>, p4a0_2_21 <dbl+lbl>,
## # servientre_1 <dbl+lbl>, servientre_2 <dbl+lbl>, servientre_3 <dbl+lbl>,
## # servientre_4 <dbl+lbl>, servientre_5 <dbl+lbl>, servientre_7 <dbl+lbl>, …Podemos ver cuántos encuestados hay por cada sexo,edad, y recuerdo de voto, contando los datos brutos o los datos utilizando la ponderación que ha calculado el CIS.
df %>%
group_by(sexo, gedad, recuerdo) %>%
summarise(total = n(),
peso_tot = sum(peso))## `summarise()` has grouped output by 'sexo', 'gedad'. You can override using the `.groups` argument.## # A tibble: 509 × 5
## # Groups: sexo, gedad [31]
## sexo gedad recuerdo total peso_tot
## <fct> <fct> <fct> <int> <dbl>
## 1 Hombre 18-24 años PP 7 6.82
## 2 Hombre 18-24 años PSOE 17 18.1
## 3 Hombre 18-24 años C's 2 2.11
## 4 Hombre 18-24 años En Comú Podem 4 4.10
## 5 Hombre 18-24 años Més Compromís 1 1.03
## 6 Hombre 18-24 años EAJ-PNV 2 2.06
## 7 Hombre 18-24 años Na+ 1 0.563
## 8 Hombre 18-24 años VOX 4 4.13
## 9 Hombre 18-24 años Unidas Podemos 13 13.7
## 10 Hombre 18-24 años BNG 2 2.05
## # … with 499 more rowsPara normalizar las siglas usamos otra tabla de lookup
siglas_cis <- read_csv("/home/jose/Rstudio_projects/raking_ejemplo/siglas_cis.csv")## Rows: 28 Columns: 2## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): recuerdo, key##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.siglas_cis## # A tibble: 28 × 2
## recuerdo key
## <chr> <chr>
## 1 No recuerda abstencion
## 2 No votó abstencion
## 3 C's CIUDADANOS
## 4 PSOE PSOE
## 5 PP PP
## 6 N.C. abstencion
## 7 VOX VOX
## 8 En blanco abstencion
## 9 Unidas Podemos PODEMOS-IU
## 10 PACMA PACMA
## # … with 18 more rows# le pegamos las siglas normalizadas
df <- df %>%
left_join(siglas_cis) ## Joining, by = "recuerdo"# Vemos los totales por recuerdo de voto , usando la ponderacińo del cis
df %>%
group_by(key) %>%
summarise(frq = sum(peso))## # A tibble: 16 × 2
## key frq
## <chr> <dbl>
## 1 abstencion 1064.
## 2 BILDU 21.5
## 3 BNG 23.6
## 4 CIUDADANOS 239.
## 5 COMPROMIS 22.1
## 6 CUP 17.4
## 7 ERC 81.9
## 8 JXCAT 40.0
## 9 MAS PAIS 28.7
## 10 OTROS 62.4
## 11 PACMA 26.4
## 12 PNV 40.5
## 13 PODEMOS-IU 426.
## 14 PP 525.
## 15 PSOE 917.
## 16 VOX 244.# Vemos total de datos en la encuesta y comprobamos que la suma de las
# ponderaciones coincide con el total de encuestados.
df %>%
summarise(n(),
sum(peso))## # A tibble: 1 × 2
## `n()` `sum(peso)`
## <int> <dbl>
## 1 3779 3779.# Convertimos a factor la variable con el recuerdo de voto normalizado
df$key <- as.factor(df$key)Ahora lo que nos hace falta es saber los totales de recuerdo de voto, sexo y edad que debería haber tenido la encuesta.
Resultados electorales
congress_2019 <- municipios(tipo_eleccion = "congreso", anno = 2019, mes = "11")
(votos_summary <- congress_2019 %>%
group_by(codigo_ccaa, codigo_provincia,
codigo_municipio, municipio) %>%
summarise(
abstencion = first(censo_ine) -
first(votos_blancos) -
first(votos_nulos) -
first(votos_candidaturas),
censo_ine = first(censo_ine),
votos_blancos = first(votos_blancos),
votos_nulos = first(votos_nulos),
votos_candidaturas = first(votos_candidaturas) ) %>%
ungroup() %>%
summarise(
abstencion = sum(abstencion, na.rm = TRUE) +
sum(votos_blancos, na.rm = TRUE) +
sum(votos_nulos, na.rm = TRUE),
censo_ine = sum(censo_ine, na.rm = TRUE),
votos_blancos = sum(votos_blancos, na.rm = TRUE),
votos_nulos = sum(votos_nulos, na.rm = TRUE),
votos_candidaturas = sum(votos_candidaturas, na.rm = TRUE)
))## `summarise()` has grouped output by 'codigo_ccaa', 'codigo_provincia', 'codigo_municipio'. You can override using the `.groups` argument.## # A tibble: 1 × 5
## abstencion censo_ine votos_blancos votos_nulos votos_candidaturas
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 10973466 34870481 216249 248543 23897015# ponemos abstencion como partido
abstencion <- votos_summary %>%
select( abstencion) %>%
mutate(siglas = "abstencion",
denominacion = "abstencion",
codigo_partido = "abstencion") %>%
rename(votos = abstencion)
votos_partidos <- congress_2019 %>%
group_by(codigo_partido, siglas, denominacion) %>%
summarise(votos = sum(votos))## `summarise()` has grouped output by 'codigo_partido', 'siglas'. You can override using the `.groups` argument.votos_final <- votos_partidos %>%
bind_rows(abstencion) %>%
bind_cols(votos_summary %>%
select( censo_ine)) %>% # debe ser pob > = 18
ungroup() %>%
mutate(prop_voto = votos/censo_ine) %>%
arrange(-prop_voto)
DT::datatable(votos_final)Como las siglas de los partidos en la info oficial y las que vienen en la encuesta no están normalizadas, me construí una tabla de “lookup” para eso.
siglas_infoelectoral <- read_csv("/home/jose/Rstudio_projects/raking_ejemplo/siglas_infoelectoral.csv")## Rows: 92 Columns: 2## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): siglas, key##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.DT::datatable(siglas_infoelectoral)(votos_final_summary <- votos_final %>%
left_join(siglas_infoelectoral) %>%
group_by(key) %>%
summarise(prop_voto = sum(prop_voto, na.rm=TRUE)))## Joining, by = "siglas"## # A tibble: 16 × 2
## key prop_voto
## <chr> <dbl>
## 1 abstencion 0.315
## 2 BILDU 0.00793
## 3 BNG 0.00343
## 4 CIUDADANOS 0.0470
## 5 COMPROMIS 0.00502
## 6 CUP 0.00702
## 7 ERC 0.0249
## 8 JXCAT 0.0151
## 9 MAS PAIS 0.0115
## 10 OTROS 0.0309
## 11 PACMA 0.00649
## 12 PNV 0.0108
## 13 PODEMOS-IU 0.0732
## 14 PP 0.144
## 15 PSOE 0.194
## 16 VOX 0.104votos_final_summary$key <- as.factor(votos_final_summary$key)
(pop_revoto <- votos_final_summary %>%
mutate(Freq = prop_voto * sum(df$peso)) %>%
select(key, Freq ) )## # A tibble: 16 × 2
## key Freq
## <fct> <dbl>
## 1 abstencion 1189.
## 2 BILDU 30.0
## 3 BNG 13.0
## 4 CIUDADANOS 177.
## 5 COMPROMIS 19.0
## 6 CUP 26.5
## 7 ERC 94.3
## 8 JXCAT 57.1
## 9 MAS PAIS 43.5
## 10 OTROS 117.
## 11 PACMA 24.5
## 12 PNV 40.9
## 13 PODEMOS-IU 276.
## 14 PP 544.
## 15 PSOE 732.
## 16 VOX 395.Y vemos que no coincide mucho con la que hay en la encuesta
df %>%
group_by(key) %>%
summarise(Freq = sum(peso))## # A tibble: 16 × 2
## key Freq
## <fct> <dbl>
## 1 abstencion 1064.
## 2 BILDU 21.5
## 3 BNG 23.6
## 4 CIUDADANOS 239.
## 5 COMPROMIS 22.1
## 6 CUP 17.4
## 7 ERC 81.9
## 8 JXCAT 40.0
## 9 MAS PAIS 28.7
## 10 OTROS 62.4
## 11 PACMA 26.4
## 12 PNV 40.5
## 13 PODEMOS-IU 426.
## 14 PP 525.
## 15 PSOE 917.
## 16 VOX 244.En la encuesta hay más personas que recuerdan haber votado al psoe que las que debería haber, así como también hay menos que recuerdan haber votado a Mas País o a Vox. Había una hipótesis por ahi que decía que el votante de derechas está infrarrepresentado en las encuestas.
Padrón
Esto es solo un csv con la info de población por sexo y edad exacta (quité los menores de 18 años)
Leemos el csv, que lamentablemente viene en encoding de windows y con separador decimal y tal.
padron <- read_delim(
"/home/jose/Rstudio_projects/raking_ejemplo/pad_2021.csv",
delim = ";",
escape_double = FALSE,
locale = locale(
date_names = "es",
decimal_mark = ",",
grouping_mark = ".",
encoding = "WINDOWS-1252"
),
trim_ws = TRUE
)## Rows: 166 Columns: 3## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ";"
## chr (1): sexo
## dbl (1): edad##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Categorizamos la edad y vemos cuales habrían sido las frecuencias de edad en la encuestas si fueran representativas de la estructura de población del padrón de 2020
pop_edad <- padron %>%
mutate(
gedad =
case_when(
edad >= 100 ~ "100 años y más",
edad >= 18 & edad <= 24 ~ "18-24 años",
edad >= 25 & edad <= 29 ~ "25-29 años",
edad >= 30 & edad <= 34 ~ "30-34 años",
edad >= 35 & edad <= 39 ~ "35-39 años",
edad >= 40 & edad <= 44 ~ "40-44 años",
edad >= 45 & edad <= 49 ~ "45-49 años",
edad >= 50 & edad <= 54 ~ "50-54 años",
edad >= 55 & edad <= 59 ~ "55-59 años",
edad >= 60 & edad <= 64 ~ "60-64 años",
edad >= 65 & edad <= 69 ~ "65-69 años",
edad >= 70 & edad <= 74 ~ "70-74 años",
edad >= 75 & edad <= 79 ~ "75-79 años",
edad >= 80 & edad <= 84 ~ "80-84 años",
edad >= 85 & edad <= 89 ~ "85-89 años",
edad >= 90 & edad <= 94 ~ "90-94 años",
edad >= 95 & edad <= 99 ~ "95-99 años",
)
) %>%
group_by(gedad) %>%
summarise(pob = sum(total)) %>%
ungroup() %>%
mutate(pct = pob/sum(pob)) %>%
mutate(Freq = pct* sum(df$peso)) %>%
select(gedad, Freq) %>%
filter(gedad!="100 años y más")
pop_sexo <- padron %>%
mutate(sexo = ifelse(sexo == "Hombres", "Hombre", "Mujer")) %>%
group_by(sexo) %>%
summarise(pob = sum(total)) %>%
ungroup() %>%
mutate(pct = pob/sum(pob)) %>%
mutate(Freq = pct* sum(df$peso)) %>%
select(sexo, Freq)
pop_sexo$sexo <- as.factor(pop_sexo$sexo)
pop_edad$gedad <- as.factor(pop_edad$gedad)
pop_edad## # A tibble: 16 × 2
## gedad Freq
## <fct> <dbl>
## 1 18-24 años 352.
## 2 25-29 años 269.
## 3 30-34 años 213.
## 4 35-39 años 313.
## 5 40-44 años 377.
## 6 45-49 años 381.
## 7 50-54 años 356.
## 8 55-59 años 362.
## 9 60-64 años 286.
## 10 65-69 años 240.
## 11 70-74 años 191.
## 12 75-79 años 187.
## 13 80-84 años 123.
## 14 85-89 años 77.9
## 15 90-94 años 41.5
## 16 95-99 años 11.1Y veamos si se parece a lo que hay en la encuesta
df %>%
group_by(gedad) %>%
summarise(Freq = sum(peso))## # A tibble: 16 × 2
## gedad Freq
## <fct> <dbl>
## 1 18-24 años 235.
## 2 25-29 años 214.
## 3 30-34 años 214.
## 4 35-39 años 268.
## 5 40-44 años 402.
## 6 45-49 años 382.
## 7 50-54 años 392.
## 8 55-59 años 336.
## 9 60-64 años 334.
## 10 65-69 años 375.
## 11 70-74 años 282.
## 12 75-79 años 177.
## 13 80-84 años 114.
## 14 85-89 años 40.0
## 15 90-94 años 12.8
## 16 95-99 años 1.05Pues en la encuesta ha caído más gente joven de la que debería, cosas que pasan.
Raking
Pues ya tenemos todo para hacer el ejercicio simple de raking.
Importamos la librería survery, comprobamos que los niveles de las variables que vamos a considerar en el raking son los mismos en los datos de las encuestas y en los dataframes auxiliares
# Comprobamos niveles
all.equal(levels(pop_revoto$key) , levels(df$key))## [1] TRUEall.equal(levels(pop_edad$gedad) , levels(df$gedad))## [1] TRUEall.equal(levels(pop_sexo$sexo), levels(df$sexo))## [1] TRUEConstruimos un diseño muestral inicial utilizando los pesos que facilita el CIS.
library(survey)## Loading required package: grid## Loading required package: Matrix##
## Attaching package: 'Matrix'## The following objects are masked from 'package:tidyr':
##
## expand, pack, unpack## Loading required package: survival##
## Attaching package: 'survey'## The following object is masked from 'package:graphics':
##
## dotchartdisenno <- svydesign(id=~1, weight=~peso,data=df)Vemos los totales por recuerdo de voto por ejemplo, con la estimación de su error estándar
svytotal(~key, disenno)## total SE
## keyabstencion 1064.301 28.1710
## keyBILDU 21.475 4.4926
## keyBNG 23.630 4.9128
## keyCIUDADANOS 238.593 15.1738
## keyCOMPROMIS 22.099 4.8096
## keyCUP 17.429 4.2181
## keyERC 81.939 9.0654
## keyJXCAT 39.984 6.3702
## keyMAS PAIS 28.734 5.4132
## keyOTROS 62.353 7.5990
## keyPACMA 26.359 5.2625
## keyPNV 40.515 6.4151
## keyPODEMOS-IU 425.598 19.7388
## keyPP 525.044 21.6608
## keyPSOE 917.318 26.7850
## keyVOX 244.059 15.4552Para hacer el raking utilizamos la funcion rake que toma argumentos el diseño muestral original, una lista con el nombre de las variables (en formula) en la encuesta , y una lista con los dataframes auxiliares cada uno con dos columnas, la variable que se corresponde con la de la encuesta y una columna numérica con el valor de cuántos individuos habría de haber en la muestra para que la distribución fuera igual a la de la población. Otros parámetros, serían el número de iteraciones máximas y el criterio de parada (epsilon) del procedimiento iterativo.
ponderacion_1 <-
rake (
design = disenno,
sample.margins = list(~gedad, ~key, ~sexo),
population.margins = list(pop_edad, pop_revoto, pop_sexo)
) Y ahora podemos comprobar qué tal lo ha hecho
Edad
pop_edad # dist poblacional## # A tibble: 16 × 2
## gedad Freq
## <fct> <dbl>
## 1 18-24 años 352.
## 2 25-29 años 269.
## 3 30-34 años 213.
## 4 35-39 años 313.
## 5 40-44 años 377.
## 6 45-49 años 381.
## 7 50-54 años 356.
## 8 55-59 años 362.
## 9 60-64 años 286.
## 10 65-69 años 240.
## 11 70-74 años 191.
## 12 75-79 años 187.
## 13 80-84 años 123.
## 14 85-89 años 77.9
## 15 90-94 años 41.5
## 16 95-99 años 11.1svytotal(~gedad, disenno) # usando ponderaciones cis## total SE
## gedad18-24 años 234.8523 15.0942
## gedad25-29 años 214.4397 14.4131
## gedad30-34 años 214.3337 14.3916
## gedad35-39 años 267.7623 16.0524
## gedad40-44 años 401.8541 19.2163
## gedad45-49 años 382.1934 18.8006
## gedad50-54 años 392.2205 19.0815
## gedad55-59 años 335.9379 17.7668
## gedad60-64 años 334.4781 17.7006
## gedad65-69 años 374.9334 18.6334
## gedad70-74 años 281.8288 16.3995
## gedad75-79 años 176.6998 13.0458
## gedad80-84 años 114.0455 10.6935
## gedad85-89 años 40.0390 6.3841
## gedad90-94 años 12.7567 3.6124
## gedad95-99 años 1.0536 1.0536svytotal(~gedad, ponderacion_1)## total SE
## gedad18-24 años 351.958 0.0022
## gedad25-29 años 269.150 0.0022
## gedad30-34 años 213.023 0.0019
## gedad35-39 años 312.727 0.0023
## gedad40-44 años 377.061 0.0024
## gedad45-49 años 380.727 0.0024
## gedad50-54 años 355.685 0.0022
## gedad55-59 años 361.652 0.0023
## gedad60-64 años 286.424 0.0018
## gedad65-69 años 239.837 0.0016
## gedad70-74 años 190.638 0.0013
## gedad75-79 años 186.745 0.0016
## gedad80-84 años 123.233 0.0013
## gedad85-89 años 77.958 0.0010
## gedad90-94 años 41.526 0.0011
## gedad95-99 años 11.083 0.0000sexo
pop_sexo## # A tibble: 2 × 2
## sexo Freq
## <fct> <dbl>
## 1 Hombre 1889.
## 2 Mujer 1891.En la encuesta original hay sobrepresentacion de mujeres
svytotal(~sexo, disenno)## total SE
## sexoHombre 1820.6 31.548
## sexoMujer 1958.8 31.519svytotal(~sexo, ponderacion_1)## total SE
## sexoHombre 1888.6 0
## sexoMujer 1890.8 0Recuerdo de voto
pop_revoto## # A tibble: 16 × 2
## key Freq
## <fct> <dbl>
## 1 abstencion 1189.
## 2 BILDU 30.0
## 3 BNG 13.0
## 4 CIUDADANOS 177.
## 5 COMPROMIS 19.0
## 6 CUP 26.5
## 7 ERC 94.3
## 8 JXCAT 57.1
## 9 MAS PAIS 43.5
## 10 OTROS 117.
## 11 PACMA 24.5
## 12 PNV 40.9
## 13 PODEMOS-IU 276.
## 14 PP 544.
## 15 PSOE 732.
## 16 VOX 395.svytotal(~key, disenno)## total SE
## keyabstencion 1064.301 28.1710
## keyBILDU 21.475 4.4926
## keyBNG 23.630 4.9128
## keyCIUDADANOS 238.593 15.1738
## keyCOMPROMIS 22.099 4.8096
## keyCUP 17.429 4.2181
## keyERC 81.939 9.0654
## keyJXCAT 39.984 6.3702
## keyMAS PAIS 28.734 5.4132
## keyOTROS 62.353 7.5990
## keyPACMA 26.359 5.2625
## keyPNV 40.515 6.4151
## keyPODEMOS-IU 425.598 19.7388
## keyPP 525.044 21.6608
## keyPSOE 917.318 26.7850
## keyVOX 244.059 15.4552svytotal(~key, ponderacion_1)## total SE
## keyabstencion 1189.358 5e-04
## keyBILDU 29.972 1e-04
## keyBNG 12.962 0e+00
## keyCIUDADANOS 177.463 2e-04
## keyCOMPROMIS 18.969 1e-04
## keyCUP 26.547 1e-04
## keyERC 94.271 2e-04
## keyJXCAT 57.097 1e-04
## keyMAS PAIS 43.529 1e-04
## keyOTROS 116.681 2e-04
## keyPACMA 24.515 1e-04
## keyPNV 40.915 1e-04
## keyPODEMOS-IU 276.473 2e-04
## keyPP 544.268 3e-04
## keyPSOE 731.849 4e-04
## keyVOX 394.559 4e-04Pues podríamos dar por buena la calibración alcanzada
Los pesos los podemos extraer usando la función weights
weights(ponderacion_1)[1:10]## 1 2 3 4 5 6 7 8
## 1.8324806 1.1606015 0.5372897 1.4168519 0.6115565 0.9731935 0.8024724 0.7280362
## 9 10
## 1.4168519 1.2670284Estimación simple de la intención de voto.
Para realizar una “buena” estimación de voto tendria que haber hecho algo más aparte del “raking”, tal vez un modelo para tener voto probable de los indecisos etcétera.
No obstante vamos a ver qué estimación saldría simplemente utilizando los pesos originales y los pesos calibrados.
(estim_cis <- svytotal(~intenciongr, disenno))## total SE
## intenciongrPP 531.4821 21.8379
## intenciongrPSOE 745.3097 24.8698
## intenciongrCiudadanos 111.9348 10.5990
## intenciongrMés Compromís 23.1522 4.9224
## intenciongrERC 61.6780 7.9014
## intenciongrJxCat 31.7818 5.6855
## intenciongrEAJ-PNV 39.4836 6.3334
## intenciongrEH Bildu 13.0444 3.5539
## intenciongrCCa-NC 10.4548 3.4812
## intenciongrNA+ 9.4790 2.4073
## intenciongrPACMA 29.3263 5.4769
## intenciongrVOX 320.9019 17.4761
## intenciongrCUP 13.3279 3.6906
## intenciongrLos Verdes 0.0000 0.0000
## intenciongrUnidas Podemos 402.1001 19.2592
## intenciongrEQUO 0.0000 0.0000
## intenciongrPAR 0.0000 0.0000
## intenciongrBNG 18.4930 4.3490
## intenciongrMÉS (PSM-Entesa) 0.0000 0.0000
## intenciongrFalange Española de las JONS 0.0000 0.0000
## intenciongrEscaños en Blanco 0.0000 0.0000
## intenciongrEspaña 2000 0.0000 0.0000
## intenciongrPartido Libertario 0.0000 0.0000
## intenciongrCHA 0.0000 0.0000
## intenciongrRecortes Cero 0.0000 0.0000
## intenciongrDirecte 68 0.0000 0.0000
## intenciongrPartido Feminista de España 0.0000 0.0000
## intenciongrGeroa Bai 0.0000 0.0000
## intenciongrBloc 0.0000 0.0000
## intenciongrConvergència 0.0000 0.0000
## intenciongrCompromís-Podemos-EUPV 0.0000 0.0000
## intenciongrUPyD 0.0000 0.0000
## intenciongrPCPE 0.0000 0.0000
## intenciongrPI 0.0000 0.0000
## intenciongrPAYJ 0.0000 0.0000
## intenciongrIGRE 0.0000 0.0000
## intenciongrPRC 3.1434 1.6474
## intenciongrUPL 0.0000 0.0000
## intenciongrRecortes Cero-Grupo Verde 0.0000 0.0000
## intenciongrCoalición Caballas 0.0000 0.0000
## intenciongrMDyC 0.0000 0.0000
## intenciongrCoalición por Melilla 0.0000 0.0000
## intenciongrPPL 0.0000 0.0000
## intenciongrMás País 60.9837 7.8825
## intenciongrPR+ 0.0000 0.0000
## intenciongrActúa 0.0000 0.0000
## intenciongrAnova-Irmandade Nacionalista 0.0000 0.0000
## intenciongrCompromiso por Galicia 0.0000 0.0000
## intenciongrBarcelona pel Canvi 0.0000 0.0000
## intenciongrZaragoza en Común 0.0000 0.0000
## intenciongrSantiago Aberta 0.0000 0.0000
## intenciongrCNxR 0.0000 0.0000
## intenciongrDemocracia Nacional 0.0000 0.0000
## intenciongrPoble Lliure 0.0000 0.0000
## intenciongrPartido Humanista 0.0000 0.0000
## intenciongrSom Valencians 0.0000 0.0000
## intenciongrConverxencia Galega 0.0000 0.0000
## intenciongrTerra Galega 0.0000 0.0000
## intenciongrTeruel Existe 2.1852 1.5450
## intenciongrExtremadura Unida 0.0000 0.0000
## intenciongrPP+C s 0.0000 0.0000
## intenciongrPDeCAT 0.0000 0.0000
## intenciongrPNC 0.0000 0.0000
## intenciongrVoto nulo 44.9441 6.7160
## intenciongrAdelante Sevilla 0.0000 0.0000
## intenciongrOtro partido 74.6794 8.5264
## intenciongrEn blanco 172.4132 13.0502
## intenciongrNo votaría 352.4158 18.0842
## intenciongrNo sabe todavía 548.6834 21.9338
## intenciongrN.C. 158.0310 12.4293(estim_calibrada <- svytotal(~intenciongr, ponderacion_1))## total SE
## intenciongrPP 566.2767 19.2580
## intenciongrPSOE 635.4325 18.5286
## intenciongrCiudadanos 96.7651 8.9299
## intenciongrMés Compromís 21.7971 3.8757
## intenciongrERC 69.4503 6.1644
## intenciongrJxCat 43.1817 5.2533
## intenciongrEAJ-PNV 37.1996 4.1088
## intenciongrEH Bildu 17.3237 4.0213
## intenciongrCCa-NC 14.3188 4.9252
## intenciongrNA+ 16.8526 4.4475
## intenciongrPACMA 31.5831 5.6846
## intenciongrVOX 434.0434 17.2445
## intenciongrCUP 18.8067 4.1303
## intenciongrLos Verdes 0.0000 0.0000
## intenciongrUnidas Podemos 302.0278 12.7507
## intenciongrEQUO 0.0000 0.0000
## intenciongrPAR 0.0000 0.0000
## intenciongrBNG 11.5789 2.4683
## intenciongrMÉS (PSM-Entesa) 0.0000 0.0000
## intenciongrFalange Española de las JONS 0.0000 0.0000
## intenciongrEscaños en Blanco 0.0000 0.0000
## intenciongrEspaña 2000 0.0000 0.0000
## intenciongrPartido Libertario 0.0000 0.0000
## intenciongrCHA 0.0000 0.0000
## intenciongrRecortes Cero 0.0000 0.0000
## intenciongrDirecte 68 0.0000 0.0000
## intenciongrPartido Feminista de España 0.0000 0.0000
## intenciongrGeroa Bai 0.0000 0.0000
## intenciongrBloc 0.0000 0.0000
## intenciongrConvergència 0.0000 0.0000
## intenciongrCompromís-Podemos-EUPV 0.0000 0.0000
## intenciongrUPyD 0.0000 0.0000
## intenciongrPCPE 0.0000 0.0000
## intenciongrPI 0.0000 0.0000
## intenciongrPAYJ 0.0000 0.0000
## intenciongrIGRE 0.0000 0.0000
## intenciongrPRC 4.1735 2.2022
## intenciongrUPL 0.0000 0.0000
## intenciongrRecortes Cero-Grupo Verde 0.0000 0.0000
## intenciongrCoalición Caballas 0.0000 0.0000
## intenciongrMDyC 0.0000 0.0000
## intenciongrCoalición por Melilla 0.0000 0.0000
## intenciongrPPL 0.0000 0.0000
## intenciongrMás País 69.1656 7.8136
## intenciongrPR+ 0.0000 0.0000
## intenciongrActúa 0.0000 0.0000
## intenciongrAnova-Irmandade Nacionalista 0.0000 0.0000
## intenciongrCompromiso por Galicia 0.0000 0.0000
## intenciongrBarcelona pel Canvi 0.0000 0.0000
## intenciongrZaragoza en Común 0.0000 0.0000
## intenciongrSantiago Aberta 0.0000 0.0000
## intenciongrCNxR 0.0000 0.0000
## intenciongrDemocracia Nacional 0.0000 0.0000
## intenciongrPoble Lliure 0.0000 0.0000
## intenciongrPartido Humanista 0.0000 0.0000
## intenciongrSom Valencians 0.0000 0.0000
## intenciongrConverxencia Galega 0.0000 0.0000
## intenciongrTerra Galega 0.0000 0.0000
## intenciongrTeruel Existe 3.6379 2.6304
## intenciongrExtremadura Unida 0.0000 0.0000
## intenciongrPP+C s 0.0000 0.0000
## intenciongrPDeCAT 0.0000 0.0000
## intenciongrPNC 0.0000 0.0000
## intenciongrVoto nulo 44.0260 6.7859
## intenciongrAdelante Sevilla 0.0000 0.0000
## intenciongrOtro partido 84.9910 9.7962
## intenciongrEn blanco 186.4136 14.3569
## intenciongrNo votaría 376.8699 19.3696
## intenciongrNo sabe todavía 524.4669 21.7009
## intenciongrN.C. 169.0461 13.5892Vamos a pintarlas. El objeto devuelto por svytotal no es muy manejable, pero podemos utilizar lo que devuelve el print.
estim_simple1 <- print(svytotal(~intenciongr, disenno))## total SE
## intenciongrPP 531.4821 21.8379
## intenciongrPSOE 745.3097 24.8698
## intenciongrCiudadanos 111.9348 10.5990
## intenciongrMés Compromís 23.1522 4.9224
## intenciongrERC 61.6780 7.9014
## intenciongrJxCat 31.7818 5.6855
## intenciongrEAJ-PNV 39.4836 6.3334
## intenciongrEH Bildu 13.0444 3.5539
## intenciongrCCa-NC 10.4548 3.4812
## intenciongrNA+ 9.4790 2.4073
## intenciongrPACMA 29.3263 5.4769
## intenciongrVOX 320.9019 17.4761
## intenciongrCUP 13.3279 3.6906
## intenciongrLos Verdes 0.0000 0.0000
## intenciongrUnidas Podemos 402.1001 19.2592
## intenciongrEQUO 0.0000 0.0000
## intenciongrPAR 0.0000 0.0000
## intenciongrBNG 18.4930 4.3490
## intenciongrMÉS (PSM-Entesa) 0.0000 0.0000
## intenciongrFalange Española de las JONS 0.0000 0.0000
## intenciongrEscaños en Blanco 0.0000 0.0000
## intenciongrEspaña 2000 0.0000 0.0000
## intenciongrPartido Libertario 0.0000 0.0000
## intenciongrCHA 0.0000 0.0000
## intenciongrRecortes Cero 0.0000 0.0000
## intenciongrDirecte 68 0.0000 0.0000
## intenciongrPartido Feminista de España 0.0000 0.0000
## intenciongrGeroa Bai 0.0000 0.0000
## intenciongrBloc 0.0000 0.0000
## intenciongrConvergència 0.0000 0.0000
## intenciongrCompromís-Podemos-EUPV 0.0000 0.0000
## intenciongrUPyD 0.0000 0.0000
## intenciongrPCPE 0.0000 0.0000
## intenciongrPI 0.0000 0.0000
## intenciongrPAYJ 0.0000 0.0000
## intenciongrIGRE 0.0000 0.0000
## intenciongrPRC 3.1434 1.6474
## intenciongrUPL 0.0000 0.0000
## intenciongrRecortes Cero-Grupo Verde 0.0000 0.0000
## intenciongrCoalición Caballas 0.0000 0.0000
## intenciongrMDyC 0.0000 0.0000
## intenciongrCoalición por Melilla 0.0000 0.0000
## intenciongrPPL 0.0000 0.0000
## intenciongrMás País 60.9837 7.8825
## intenciongrPR+ 0.0000 0.0000
## intenciongrActúa 0.0000 0.0000
## intenciongrAnova-Irmandade Nacionalista 0.0000 0.0000
## intenciongrCompromiso por Galicia 0.0000 0.0000
## intenciongrBarcelona pel Canvi 0.0000 0.0000
## intenciongrZaragoza en Común 0.0000 0.0000
## intenciongrSantiago Aberta 0.0000 0.0000
## intenciongrCNxR 0.0000 0.0000
## intenciongrDemocracia Nacional 0.0000 0.0000
## intenciongrPoble Lliure 0.0000 0.0000
## intenciongrPartido Humanista 0.0000 0.0000
## intenciongrSom Valencians 0.0000 0.0000
## intenciongrConverxencia Galega 0.0000 0.0000
## intenciongrTerra Galega 0.0000 0.0000
## intenciongrTeruel Existe 2.1852 1.5450
## intenciongrExtremadura Unida 0.0000 0.0000
## intenciongrPP+C s 0.0000 0.0000
## intenciongrPDeCAT 0.0000 0.0000
## intenciongrPNC 0.0000 0.0000
## intenciongrVoto nulo 44.9441 6.7160
## intenciongrAdelante Sevilla 0.0000 0.0000
## intenciongrOtro partido 74.6794 8.5264
## intenciongrEn blanco 172.4132 13.0502
## intenciongrNo votaría 352.4158 18.0842
## intenciongrNo sabe todavía 548.6834 21.9338
## intenciongrN.C. 158.0310 12.4293estim_simple2 <- print(svytotal(~intenciongr, ponderacion_1))## total SE
## intenciongrPP 566.2767 19.2580
## intenciongrPSOE 635.4325 18.5286
## intenciongrCiudadanos 96.7651 8.9299
## intenciongrMés Compromís 21.7971 3.8757
## intenciongrERC 69.4503 6.1644
## intenciongrJxCat 43.1817 5.2533
## intenciongrEAJ-PNV 37.1996 4.1088
## intenciongrEH Bildu 17.3237 4.0213
## intenciongrCCa-NC 14.3188 4.9252
## intenciongrNA+ 16.8526 4.4475
## intenciongrPACMA 31.5831 5.6846
## intenciongrVOX 434.0434 17.2445
## intenciongrCUP 18.8067 4.1303
## intenciongrLos Verdes 0.0000 0.0000
## intenciongrUnidas Podemos 302.0278 12.7507
## intenciongrEQUO 0.0000 0.0000
## intenciongrPAR 0.0000 0.0000
## intenciongrBNG 11.5789 2.4683
## intenciongrMÉS (PSM-Entesa) 0.0000 0.0000
## intenciongrFalange Española de las JONS 0.0000 0.0000
## intenciongrEscaños en Blanco 0.0000 0.0000
## intenciongrEspaña 2000 0.0000 0.0000
## intenciongrPartido Libertario 0.0000 0.0000
## intenciongrCHA 0.0000 0.0000
## intenciongrRecortes Cero 0.0000 0.0000
## intenciongrDirecte 68 0.0000 0.0000
## intenciongrPartido Feminista de España 0.0000 0.0000
## intenciongrGeroa Bai 0.0000 0.0000
## intenciongrBloc 0.0000 0.0000
## intenciongrConvergència 0.0000 0.0000
## intenciongrCompromís-Podemos-EUPV 0.0000 0.0000
## intenciongrUPyD 0.0000 0.0000
## intenciongrPCPE 0.0000 0.0000
## intenciongrPI 0.0000 0.0000
## intenciongrPAYJ 0.0000 0.0000
## intenciongrIGRE 0.0000 0.0000
## intenciongrPRC 4.1735 2.2022
## intenciongrUPL 0.0000 0.0000
## intenciongrRecortes Cero-Grupo Verde 0.0000 0.0000
## intenciongrCoalición Caballas 0.0000 0.0000
## intenciongrMDyC 0.0000 0.0000
## intenciongrCoalición por Melilla 0.0000 0.0000
## intenciongrPPL 0.0000 0.0000
## intenciongrMás País 69.1656 7.8136
## intenciongrPR+ 0.0000 0.0000
## intenciongrActúa 0.0000 0.0000
## intenciongrAnova-Irmandade Nacionalista 0.0000 0.0000
## intenciongrCompromiso por Galicia 0.0000 0.0000
## intenciongrBarcelona pel Canvi 0.0000 0.0000
## intenciongrZaragoza en Común 0.0000 0.0000
## intenciongrSantiago Aberta 0.0000 0.0000
## intenciongrCNxR 0.0000 0.0000
## intenciongrDemocracia Nacional 0.0000 0.0000
## intenciongrPoble Lliure 0.0000 0.0000
## intenciongrPartido Humanista 0.0000 0.0000
## intenciongrSom Valencians 0.0000 0.0000
## intenciongrConverxencia Galega 0.0000 0.0000
## intenciongrTerra Galega 0.0000 0.0000
## intenciongrTeruel Existe 3.6379 2.6304
## intenciongrExtremadura Unida 0.0000 0.0000
## intenciongrPP+C s 0.0000 0.0000
## intenciongrPDeCAT 0.0000 0.0000
## intenciongrPNC 0.0000 0.0000
## intenciongrVoto nulo 44.0260 6.7859
## intenciongrAdelante Sevilla 0.0000 0.0000
## intenciongrOtro partido 84.9910 9.7962
## intenciongrEn blanco 186.4136 14.3569
## intenciongrNo votaría 376.8699 19.3696
## intenciongrNo sabe todavía 524.4669 21.7009
## intenciongrN.C. 169.0461 13.5892cis_estim <- estim_simple1 %>%
as.data.frame() %>% # as.data.frame para no perder los nombre de filas
rownames_to_column(var = "partido") %>%
mutate(partido = str_sub(partido, 12, -1),
tot_low = total - 1.96 * SE , # intervalos simples
tot_high = total + 1.96 * SE,
pct_voto = total / 3779.429,
pct_voto_low = tot_low / 3779.429,
pct_voto_high = tot_high / 3779.429
)
cañi_estim <- estim_simple2 %>%
as.data.frame() %>% # as.data.frame para no perder los nombre de filas
rownames_to_column(var = "partido") %>%
mutate(partido = str_sub(partido, 12, -1),
tot_low = total - 1.96 * SE ,
tot_high = total + 1.96 * SE,
pct_voto = total / 3779.429,
pct_voto_low = tot_low / 3779.429,
pct_voto_high = tot_high / 3779.429
)
p_cis <- cis_estim %>%
top_n(22, pct_voto) %>%
ggplot(aes(y = reorder(partido, pct_voto ), x = pct_voto)) +
geom_point(color = "darkred", size = rel(3)) +
geom_errorbarh(aes(xmin = pct_voto_low, xmax = pct_voto_high)) +
scale_x_continuous(labels = scales::percent,
limits = c(0, 0.22)) +
labs(title = "Estimación intención voto (CIS)",
subtitle = "Usando ponderación cis",
x = "Proporción voto",
y = "Partido")
p_cañi <- cañi_estim %>%
top_n(22, pct_voto) %>%
ggplot(aes(y = reorder(partido, pct_voto ), x = pct_voto)) +
geom_point(color = "darkblue", size = rel(3)) +
geom_errorbarh(aes(xmin = pct_voto_low, xmax = pct_voto_high)) +
scale_x_continuous(labels = scales::percent,
limits = c(0, 0.22)) +
labs(title = "Estimación intención voto (con raking) ",
subtitle = "Ajustando ponderación por edad,\nsexo y recuerdo voto",
x = "Proporción voto",
y = "Partido")
p_cis + p_cañi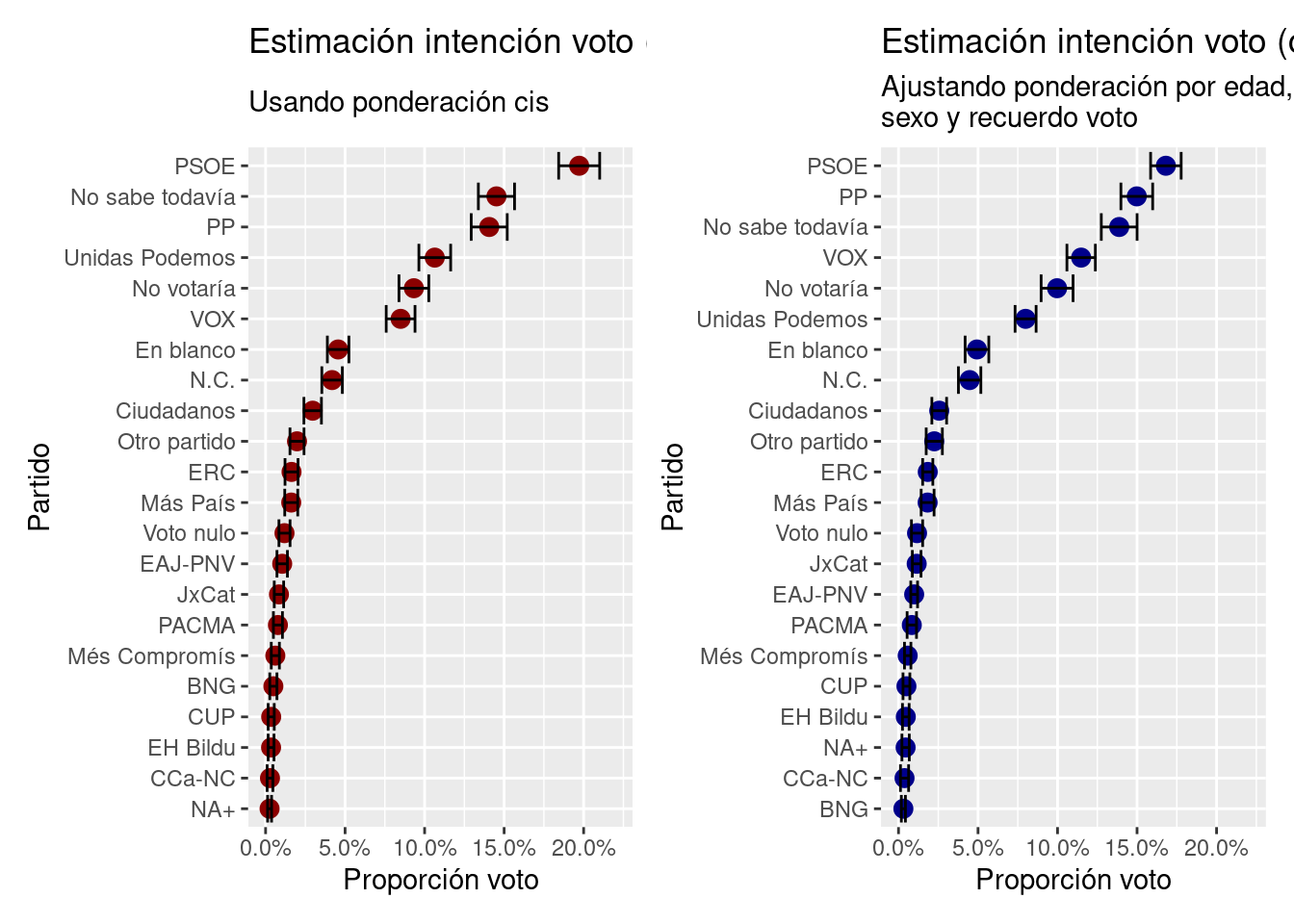
Nota.
En vez de raking es usual utilizar modelos como MRP (multilevel regression and estratification), pero este último tiene el incoveniente (aunque muchas otras ventajas) de que necesita saber la distribución conjunta de las variables por las que se postestrafifica.
Aquí os dejo un artículo interesante