Y seguimos dando vueltas a los datos de post anteriores. Siempre hay quien dice que el bayesiano no sirve para big data y qué se acaba el universo antes de que termine de ajustar tu modelo (esto último creo que se lo he dicho yo alguna vez a Carlos).
Pero ya hemos visto en los dos post anteriores que podemos condensar los datos en menos filas sin perder información, así que , ¿por qué no utilizar un modelo bayesiano?
Del post anterior
library(tidyverse)
library(sparklyr)
sc <- spark_connect(master = "local")
tmp <- sc %>% # vuelvo al pipe de magrittr
spark_read_parquet(path = here::here("data/bd_pobres.parquet" ))
df_spark <- tmp %>%
mutate(
edad_cat = case_when(
edad <= 20 ~ "<21",
edad <= 40 ~ "21- 40",
edad <= 50 ~ "41-50",
edad <= 60 ~ "40-60",
edad > 60 ~ ">60"
)
)
particiones <- df_spark %>% sdf_random_split(training = 0.6, test = 0.4)
train <- particiones$training
test <- particiones$test
train_local <- train %>%
group_by(segmento,
tipo,
valor_cliente,
edad_cat) %>%
count() %>%
collect() %>%
# ponemos las variables categóricas a tipo factor
mutate(across(where(is.character), as_factor))
test_local <- test %>%
group_by(segmento,
tipo,
valor_cliente,
edad_cat) %>%
count() %>%
collect() %>%
# ponemos las variables categóricas a tipo factor
mutate(across(where(is.character), as_factor))
spark_disconnect(sc)Y tenemos nuestros conjuntos de train y de test en local
DT::datatable(train_local)Modelo bayesiano.
Pues ahora vamos a probar a hacer un modelo bayesiano jerárquico, podríamos hacer el equivalente a glmer usando la librería rstanarm y ajustar varias regresiones logísticas independientes, pero en vez de eso vamos a ver como ajustar directamente la distribución multinomial usando brms.
Los modelos serían algo así como
$$ \[\begin{equation} ans \sim Multinomial(\boldsymbol{\theta}) \end{equation}\]
$$ Dónde \(\boldsymbol{\theta} = \{\theta_{Rec}, \theta_{Best}, \theta_{Neut}, \theta_{\text{No_way}}\}\)
Lo bueno de stan y de brms es que se puede modelar directamente la Multinomial, es decir, el número de “éxitos” en cada categoría dado un número de intentos. En brms podemos usar trials para especificarlo. Sería el equivalente al weights en glmer. De esta forma podemos trabajar con los datos agregados en vez de tenerlos individuales. Si tengo, 1000 clientes con edad < 21 y valor_cliente = 8, en vez de poner 1000 filas, pongo una columna de frecuencias, que es lo que hemos hecho.
Librerías
Yo uso cmdstan como backend para brms en vez de rstan, está más actualizado y tarda menos en muestrear.
# Core libraries
library(tidyverse)
library(tidybayes)
library(brms)
library(cmdstanr)
# For beauty plots
library(ggridges)
## Using all cores. 12 in my machine
options(mc.cores = parallel::detectCores())
set_cmdstan_path("~/cmdstan/")Adecuando los datos
Para poder ajustar el modelo de regresión multinomial se necesita tener los datos de una determinada forma, básicamente tener una columna de tipo matriz. Para eso vamos a pivotar los datos y usar cbind
Pivotamos
train_wider <- train_local %>%
pivot_wider(
id_cols = c(tipo, valor_cliente, edad_cat),
names_from = segmento,
values_from = n) %>%
mutate(
across(where(is.numeric), ~replace_na(.x, 0)),
total = Rec + Neut + Best + No_way
)
test_wider <- test_local %>%
pivot_wider(
id_cols = c(tipo, valor_cliente, edad_cat),
names_from = segmento,
values_from = n) %>%
mutate(
across(where(is.numeric), ~replace_na(.x, 0)),
total = Rec + Neut + Best + No_way
)DT::datatable(train_wider)Y ahora unimos las columnas que indican el conteo en cada perfil de Rec, Best, Neut y NoWay en un columna que es una matriz
# lo hacemos solo para el train, para el test no hace falta
train_wider$cell_counts <- with(train_wider, cbind(Rec, Best, Neut, No_way))
class(train_wider$cell_counts)## [1] "matrix" "array"DT::datatable( train_wider %>%
select(tipo, valor_cliente,
cell_counts, everything()
))Pues ya podemos ajustar el modelo. Brms tiene una función get_prior para poner las priors por defecto.
Voy a usar un modelo con efectos aleatorios que tarda unos pocos minutos, pero si usamos cell_counts | trials(total) ~ edad_cat + valor_cliente el modelo se ajusta en menos de 60 segundos. Bueno, vamos a verlo
Ajuste de los modelos
Modelo efectos fijos
formula_efectos_fijos <- brmsformula(
cell_counts | trials(total) ~ edad_cat + valor_cliente
)
# get priors
priors <- get_prior(formula_efectos_fijos, train_wider, family = multinomial())
tictoc::tic("Modelo efectos fijos")
model_multinomial1 <- brm(formula_efectos_fijos, train_wider, multinomial(), priors,
iter = 4000, warmup = 1000, cores = 4, chains = 4,
seed = 10,
backend = "cmdstanr",
refresh = 0
)## Running MCMC with 4 parallel chains...
##
## Chain 4 finished in 33.4 seconds.
## Chain 2 finished in 35.4 seconds.
## Chain 1 finished in 36.2 seconds.
## Chain 3 finished in 39.3 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 36.1 seconds.
## Total execution time: 39.5 seconds.tictoc::toc()## Modelo efectos fijos: 53.512 sec elapsedModelo con efectos aleatorios
Y tarda unos 9 minutos o así
formula <- brmsformula(
cell_counts | trials(total) ~ (1|edad_cat) + (1|valor_cliente
))
# get priors
priors <- get_prior(formula, train_wider, family = multinomial())Podemos ver las priors que ha considerado por defecto. Y vemos las priors que ha tomado para modelar la distribución de las \(\sigma\) asociadas a edad_cat y valor_cliente
priors## prior class coef group resp dpar nlpar
## (flat) Intercept
## student_t(3, 84.5, 125.3) Intercept muBest
## student_t(3, 0, 2.5) sd muBest
## student_t(3, 0, 2.5) sd edad_cat muBest
## student_t(3, 0, 2.5) sd Intercept edad_cat muBest
## student_t(3, 0, 2.5) sd valor_cliente muBest
## student_t(3, 0, 2.5) sd Intercept valor_cliente muBest
## student_t(3, 84.5, 125.3) Intercept muNeut
## student_t(3, 0, 2.5) sd muNeut
## student_t(3, 0, 2.5) sd edad_cat muNeut
## student_t(3, 0, 2.5) sd Intercept edad_cat muNeut
## student_t(3, 0, 2.5) sd valor_cliente muNeut
## student_t(3, 0, 2.5) sd Intercept valor_cliente muNeut
## student_t(3, 84.5, 125.3) Intercept muNoway
## student_t(3, 0, 2.5) sd muNoway
## student_t(3, 0, 2.5) sd edad_cat muNoway
## student_t(3, 0, 2.5) sd Intercept edad_cat muNoway
## student_t(3, 0, 2.5) sd valor_cliente muNoway
## student_t(3, 0, 2.5) sd Intercept valor_cliente muNoway
## bound source
## default
## default
## default
## (vectorized)
## (vectorized)
## (vectorized)
## (vectorized)
## default
## default
## (vectorized)
## (vectorized)
## (vectorized)
## (vectorized)
## default
## default
## (vectorized)
## (vectorized)
## (vectorized)
## (vectorized)tictoc::tic("modelo mixto")
model_multinomial2 <- brm(formula, train_wider, multinomial(), priors,
iter = 4000, warmup = 1000, cores = 4, chains = 4,
seed = 10,
backend = "cmdstanr",
refresh = 0
)## Running MCMC with 4 parallel chains...
##
## Chain 1 finished in 571.1 seconds.
## Chain 2 finished in 571.2 seconds.
## Chain 4 finished in 573.9 seconds.
## Chain 3 finished in 577.2 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 573.3 seconds.
## Total execution time: 577.4 seconds.tictoc::toc()## modelo mixto: 601.582 sec elapsedPodemos ver el modelo con
summary(model_multinomial2)## Family: multinomial
## Links: muBest = logit; muNeut = logit; muNoway = logit
## Formula: cell_counts | trials(total) ~ (1 | edad_cat) + (1 | valor_cliente)
## Data: train_wider (Number of observations: 185)
## Samples: 4 chains, each with iter = 4000; warmup = 1000; thin = 1;
## total post-warmup samples = 12000
##
## Group-Level Effects:
## ~edad_cat (Number of levels: 5)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS
## sd(muBest_Intercept) 0.99 0.50 0.44 2.33 1.00 1976
## sd(muNeut_Intercept) 0.53 0.31 0.21 1.41 1.00 2110
## sd(muNoway_Intercept) 0.54 0.29 0.24 1.30 1.00 2606
## Tail_ESS
## sd(muBest_Intercept) 3333
## sd(muNeut_Intercept) 3499
## sd(muNoway_Intercept) 3934
##
## ~valor_cliente (Number of levels: 10)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS
## sd(muBest_Intercept) 0.97 0.30 0.58 1.74 1.00 1614
## sd(muNeut_Intercept) 0.51 0.15 0.31 0.89 1.01 1581
## sd(muNoway_Intercept) 1.74 0.48 1.08 2.92 1.01 1281
## Tail_ESS
## sd(muBest_Intercept) 2921
## sd(muNeut_Intercept) 2966
## sd(muNoway_Intercept) 2130
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## muBest_Intercept -0.07 0.61 -1.27 1.17 1.01 770 1356
## muNeut_Intercept 1.06 0.31 0.46 1.70 1.00 1112 2175
## muNoway_Intercept 0.78 0.63 -0.43 2.06 1.01 746 1339
##
## Samples were drawn using sample(hmc). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Pintarlo
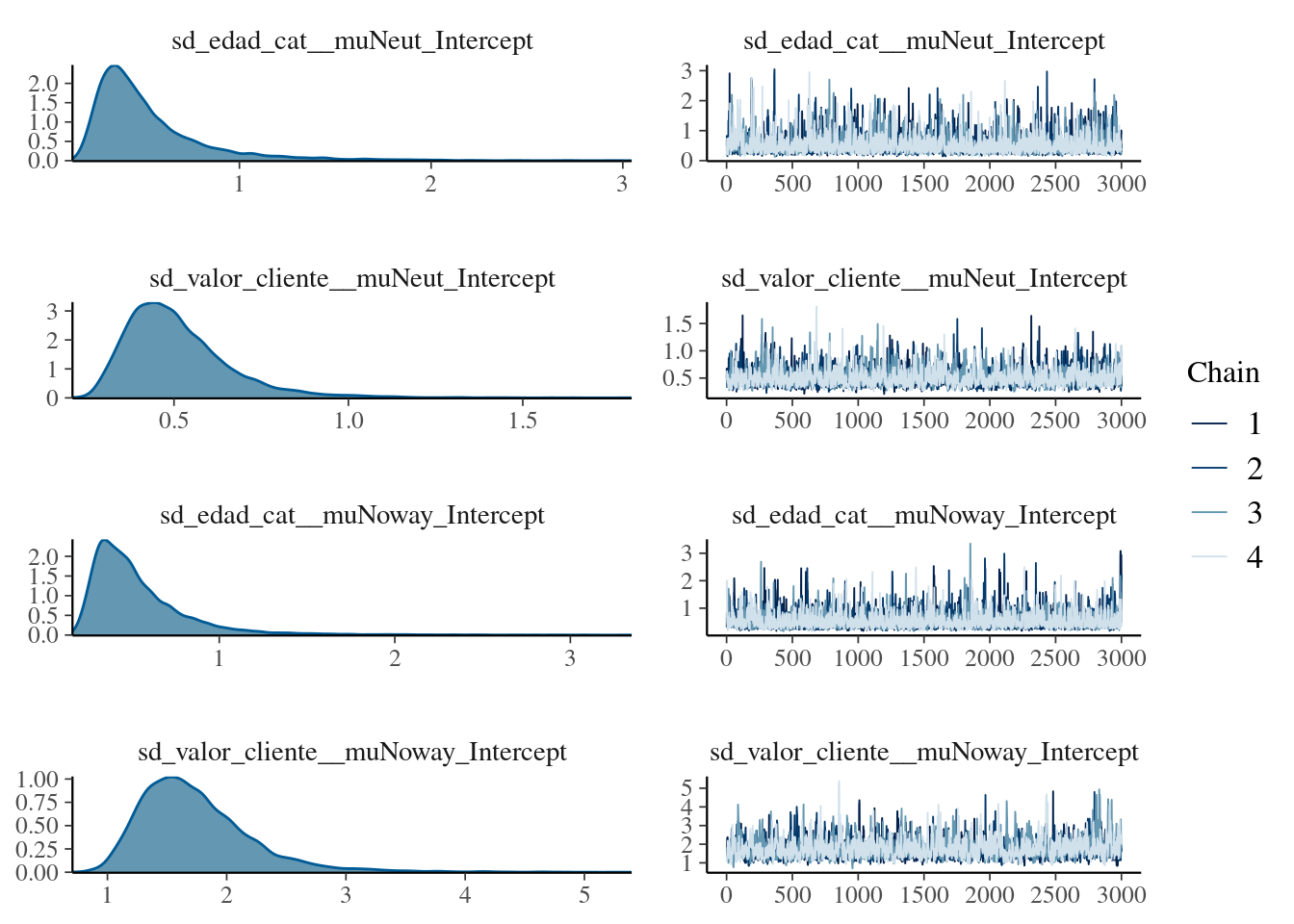
plot(model_multinomial2, ask = FALSE)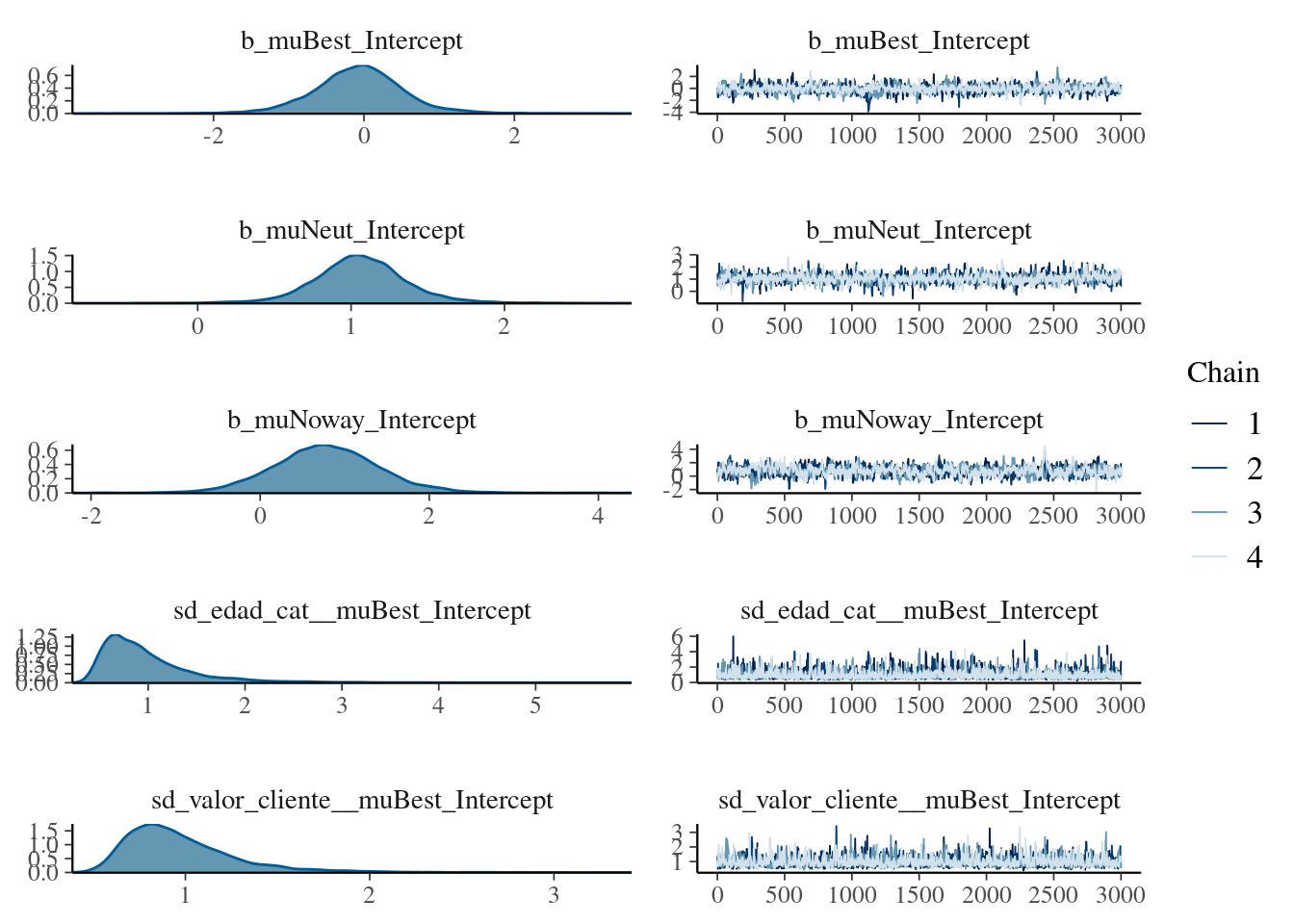
E incluso ver el modelo en stan
model_multinomial2$model## // generated with brms 2.15.0
## functions {
## /* multinomial-logit log-PMF
## * Args:
## * y: array of integer response values
## * mu: vector of category logit probabilities
## * Returns:
## * a scalar to be added to the log posterior
## */
## real multinomial_logit2_lpmf(int[] y, vector mu) {
## return multinomial_lpmf(y | softmax(mu));
## }
## }
## data {
## int<lower=1> N; // total number of observations
## int<lower=2> ncat; // number of categories
## int Y[N, ncat]; // response array
## int trials[N]; // number of trials
## // data for group-level effects of ID 1
## int<lower=1> N_1; // number of grouping levels
## int<lower=1> M_1; // number of coefficients per level
## int<lower=1> J_1[N]; // grouping indicator per observation
## // group-level predictor values
## vector[N] Z_1_muBest_1;
## // data for group-level effects of ID 2
## int<lower=1> N_2; // number of grouping levels
## int<lower=1> M_2; // number of coefficients per level
## int<lower=1> J_2[N]; // grouping indicator per observation
## // group-level predictor values
## vector[N] Z_2_muBest_1;
## // data for group-level effects of ID 3
## int<lower=1> N_3; // number of grouping levels
## int<lower=1> M_3; // number of coefficients per level
## int<lower=1> J_3[N]; // grouping indicator per observation
## // group-level predictor values
## vector[N] Z_3_muNeut_1;
## // data for group-level effects of ID 4
## int<lower=1> N_4; // number of grouping levels
## int<lower=1> M_4; // number of coefficients per level
## int<lower=1> J_4[N]; // grouping indicator per observation
## // group-level predictor values
## vector[N] Z_4_muNeut_1;
## // data for group-level effects of ID 5
## int<lower=1> N_5; // number of grouping levels
## int<lower=1> M_5; // number of coefficients per level
## int<lower=1> J_5[N]; // grouping indicator per observation
## // group-level predictor values
## vector[N] Z_5_muNoway_1;
## // data for group-level effects of ID 6
## int<lower=1> N_6; // number of grouping levels
## int<lower=1> M_6; // number of coefficients per level
## int<lower=1> J_6[N]; // grouping indicator per observation
## // group-level predictor values
## vector[N] Z_6_muNoway_1;
## int prior_only; // should the likelihood be ignored?
## }
## transformed data {
## }
## parameters {
## real Intercept_muBest; // temporary intercept for centered predictors
## real Intercept_muNeut; // temporary intercept for centered predictors
## real Intercept_muNoway; // temporary intercept for centered predictors
## vector<lower=0>[M_1] sd_1; // group-level standard deviations
## vector[N_1] z_1[M_1]; // standardized group-level effects
## vector<lower=0>[M_2] sd_2; // group-level standard deviations
## vector[N_2] z_2[M_2]; // standardized group-level effects
## vector<lower=0>[M_3] sd_3; // group-level standard deviations
## vector[N_3] z_3[M_3]; // standardized group-level effects
## vector<lower=0>[M_4] sd_4; // group-level standard deviations
## vector[N_4] z_4[M_4]; // standardized group-level effects
## vector<lower=0>[M_5] sd_5; // group-level standard deviations
## vector[N_5] z_5[M_5]; // standardized group-level effects
## vector<lower=0>[M_6] sd_6; // group-level standard deviations
## vector[N_6] z_6[M_6]; // standardized group-level effects
## }
## transformed parameters {
## vector[N_1] r_1_muBest_1; // actual group-level effects
## vector[N_2] r_2_muBest_1; // actual group-level effects
## vector[N_3] r_3_muNeut_1; // actual group-level effects
## vector[N_4] r_4_muNeut_1; // actual group-level effects
## vector[N_5] r_5_muNoway_1; // actual group-level effects
## vector[N_6] r_6_muNoway_1; // actual group-level effects
## r_1_muBest_1 = (sd_1[1] * (z_1[1]));
## r_2_muBest_1 = (sd_2[1] * (z_2[1]));
## r_3_muNeut_1 = (sd_3[1] * (z_3[1]));
## r_4_muNeut_1 = (sd_4[1] * (z_4[1]));
## r_5_muNoway_1 = (sd_5[1] * (z_5[1]));
## r_6_muNoway_1 = (sd_6[1] * (z_6[1]));
## }
## model {
## // likelihood including constants
## if (!prior_only) {
## // initialize linear predictor term
## vector[N] muBest = Intercept_muBest + rep_vector(0.0, N);
## // initialize linear predictor term
## vector[N] muNeut = Intercept_muNeut + rep_vector(0.0, N);
## // initialize linear predictor term
## vector[N] muNoway = Intercept_muNoway + rep_vector(0.0, N);
## // linear predictor matrix
## vector[ncat] mu[N];
## for (n in 1:N) {
## // add more terms to the linear predictor
## muBest[n] += r_1_muBest_1[J_1[n]] * Z_1_muBest_1[n] + r_2_muBest_1[J_2[n]] * Z_2_muBest_1[n];
## }
## for (n in 1:N) {
## // add more terms to the linear predictor
## muNeut[n] += r_3_muNeut_1[J_3[n]] * Z_3_muNeut_1[n] + r_4_muNeut_1[J_4[n]] * Z_4_muNeut_1[n];
## }
## for (n in 1:N) {
## // add more terms to the linear predictor
## muNoway[n] += r_5_muNoway_1[J_5[n]] * Z_5_muNoway_1[n] + r_6_muNoway_1[J_6[n]] * Z_6_muNoway_1[n];
## }
## for (n in 1:N) {
## mu[n] = transpose([0, muBest[n], muNeut[n], muNoway[n]]);
## }
## for (n in 1:N) {
## target += multinomial_logit2_lpmf(Y[n] | mu[n]);
## }
## }
## // priors including constants
## target += student_t_lpdf(Intercept_muBest | 3, 84.5, 125.3);
## target += student_t_lpdf(Intercept_muNeut | 3, 84.5, 125.3);
## target += student_t_lpdf(Intercept_muNoway | 3, 84.5, 125.3);
## target += student_t_lpdf(sd_1 | 3, 0, 2.5)
## - 1 * student_t_lccdf(0 | 3, 0, 2.5);
## target += std_normal_lpdf(z_1[1]);
## target += student_t_lpdf(sd_2 | 3, 0, 2.5)
## - 1 * student_t_lccdf(0 | 3, 0, 2.5);
## target += std_normal_lpdf(z_2[1]);
## target += student_t_lpdf(sd_3 | 3, 0, 2.5)
## - 1 * student_t_lccdf(0 | 3, 0, 2.5);
## target += std_normal_lpdf(z_3[1]);
## target += student_t_lpdf(sd_4 | 3, 0, 2.5)
## - 1 * student_t_lccdf(0 | 3, 0, 2.5);
## target += std_normal_lpdf(z_4[1]);
## target += student_t_lpdf(sd_5 | 3, 0, 2.5)
## - 1 * student_t_lccdf(0 | 3, 0, 2.5);
## target += std_normal_lpdf(z_5[1]);
## target += student_t_lpdf(sd_6 | 3, 0, 2.5)
## - 1 * student_t_lccdf(0 | 3, 0, 2.5);
## target += std_normal_lpdf(z_6[1]);
## }
## generated quantities {
## // actual population-level intercept
## real b_muBest_Intercept = Intercept_muBest;
## // actual population-level intercept
## real b_muNeut_Intercept = Intercept_muNeut;
## // actual population-level intercept
## real b_muNoway_Intercept = Intercept_muNoway;
## }Viendo el código en stan que genera brms utiliza parametrización con multinomial_lpmf que toma el log de la probabilidad de la multinomial y usa softmax sobre el predictor lineal. multivariate_discrete_stan
En la parte de functions tiene
real multinomial_logit2_lpmf(int[] y, vector mu) {
return multinomial_lpmf(y | softmax(mu));
}Y en la de model
for (n in 1:N) {
target += multinomial_logit2_lpmf(Y[n] | mu[n]);
}Y en la parte del predictor lineal mu[n] es dónde ha ido añadiendo los group levels effects.
Por ejemplo la parte de la edad_cat para la categoría Best está en la parte de transformed parameters dónde z_1[1] se modela como normal y sd_1 como una t de student
r_1_muBest_1 = (sd_1[1] * (z_1[1]));Y en la parte de model va añadiendo términos al muBest que es al final el que entra en la parte de la verosimilitud.
muBest[n] += r_1_muBest_1[J_1[n]] * Z_1_muBest_1[n] + r_2_muBest_1[J_2[n]] * Z_2_muBest_1[n];Aquí añade el efecto de la edad r_1_muBest_1[J_1[n]] lo multiplica por Z_1_mubest_1[n] que es el indicador en los datos de la matriz Z para los efectos aleatorios (todo igual a 1) y luego añade el efecto de la variable valor_cliente.
La verdad es que eel bloque model que genera brms es un poco complicado. Imagino que genera código optimizado. Para los que quieran verlo todo con stan directamente este libro tiene un ejemplo básico
En brms tenemos la función make_standata que nos genera los datos tal y como se los pasa a Stan.
datos_stan <- make_standata(formula, data = train_wider,
family = multinomial(),
prior = priors)names(datos_stan)## [1] "N" "Y" "trials" "ncat"
## [5] "K_muBest" "X_muBest" "Z_1_muBest_1" "Z_2_muBest_1"
## [9] "K_muNeut" "X_muNeut" "Z_3_muNeut_1" "Z_4_muNeut_1"
## [13] "K_muNoway" "X_muNoway" "Z_5_muNoway_1" "Z_6_muNoway_1"
## [17] "J_1" "J_2" "J_3" "J_4"
## [21] "J_5" "J_6" "N_1" "M_1"
## [25] "NC_1" "N_2" "M_2" "NC_2"
## [29] "N_3" "M_3" "NC_3" "N_4"
## [33] "M_4" "NC_4" "N_5" "M_5"
## [37] "NC_5" "N_6" "M_6" "NC_6"
## [41] "prior_only"# datos
datos_stan$N## [1] 185# numero de niveles edad
datos_stan$N_1## [1] 5# numero niveles valor_cliente
datos_stan$N_2## [1] 10En los J_1, J_2, está codificado a que nivel de edad y valor_cliente perteneces esa fila. J_3 y J_4 es igual a J_1 y J_2. Lo repite para cada categoría de respuesta.
datos_stan$J_1## [1] 1 2 2 3 4 2 4 5 1 5 3 3 4 2 2 2 3 4 1 3 4 4 5 1 2 2 3 4 5 1 1 2 3 3 4 1 3
## [38] 4 4 1 1 1 2 5 1 2 4 4 1 1 2 4 4 5 5 5 2 3 4 5 2 2 4 4 4 5 5 3 4 1 4 1 3 4
## [75] 1 1 2 2 3 4 5 5 4 5 1 3 3 5 4 5 1 1 3 4 5 1 1 3 5 1 2 3 3 1 4 5 3 1 1 3 1
## [112] 1 2 3 3 1 2 3 1 2 2 5 3 3 2 3 5 1 4 5 3 5 5 2 4 3 5 1 2 2 5 1 3 2 1 2 4 2
## [149] 3 1 3 4 4 1 3 4 5 3 4 5 2 4 5 3 4 2 1 4 5 1 2 2 5 1 2 3 2 5 2 3 4 3 2 2 5datos_stan$J_2## [1] 1 1 1 1 1 2 2 3 3 3 3 3 3 4 5 5 5 5 6 6 6 6 7 7 7
## [26] 7 7 7 8 8 8 8 8 8 8 9 9 9 9 10 10 1 1 2 2 2 2 2 3 3
## [51] 3 3 3 4 4 4 4 4 4 5 5 5 5 5 5 6 6 6 6 7 7 8 8 8 9
## [76] 9 9 9 9 9 1 1 1 2 2 2 2 3 3 4 4 4 4 4 5 5 5 5 6 6
## [101] 6 6 6 7 7 8 10 1 1 1 2 2 2 2 3 3 3 3 5 6 6 7 7 7 8
## [126] 8 9 9 9 1 1 2 2 2 2 5 3 4 4 4 5 5 5 6 8 8 8 9 9 10
## [151] 1 1 1 4 4 4 7 7 7 8 8 8 9 2 4 3 6 6 7 7 7 1 5 6 9
## [176] 9 3 6 7 10 10 4 10 10 8Pero yo estoy interesado en ver 2 cosas, como de bien predice sobre test y cuál es la probabilidad de cada clase condicionada a cada perfil
Predicción
Podemos obtener o bien todas las estimaciones o resumirlas
predicciones_test <- posterior_predict(model_multinomial2, newdata = test_wider)Aquí lo que tenemos es un array de dimensiones 12000, 180, 4 . Que se corresponde a tener las 12000 estimaciones ( 4 cadenas x 3000 muestras efectivas) , para las 180 filas del conjunto de test
dim(predicciones_test)## [1] 12000 177 4Por ejemplo para la fila 35 de test que sería
test_wider[1,]## # A tibble: 1 x 8
## tipo valor_cliente edad_cat Rec Best Neut No_way total
## <fct> <dbl> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 C 0 21- 40 122 98 294 62 576Y las predicciones (de la 1 a la 20) de las 1200
predicciones_test[1:20, 1, ]## Rec Best Neut No_way
## [1,] 62 122 228 164
## [2,] 60 134 217 165
## [3,] 72 110 229 165
## [4,] 63 106 243 164
## [5,] 65 112 223 176
## [6,] 56 128 216 176
## [7,] 57 109 231 179
## [8,] 67 118 221 170
## [9,] 65 131 207 173
## [10,] 53 123 217 183
## [11,] 72 120 221 163
## [12,] 67 109 225 175
## [13,] 63 117 221 175
## [14,] 72 131 205 168
## [15,] 73 125 219 159
## [16,] 73 114 238 151
## [17,] 58 136 222 160
## [18,] 71 119 226 160
## [19,] 61 119 212 184
## [20,] 63 129 216 168Como ahora todo es tidy voy a usar tidybayespara tener esa predicción.
predicciones_tidy <- test_wider %>%
add_fitted_draws(model_multinomial2) Y se nos ha quedado un dataset muy muy grande
dim(predicciones_tidy)## [1] 8496000 14DT::datatable(predicciones_tidy %>%
ungroup() %>%
sample_n(30) %>%
select(edad_cat, valor_cliente,.category, .value))Pero si quisiéramos pintar las probabilidades estimadas tendríamos que dividir el valor predicho de cada categoría por el total de clientes en cada fila del conjunto de datos de test. Hay una forma más sencilla construyendo un conjunto de datos que tenga todas las combinaciones de edad_cat y valor_cliente y añadiendo columna totalcon valor 1.
fake_data <- test_wider %>%
tidyr::expand(edad_cat, valor_cliente) %>%
mutate(total = 1)df_pintar <- fake_data %>%
add_fitted_draws(model_multinomial2) %>%
mutate(valor_cliente = as_factor(valor_cliente))De esta forma, al tener total = 1, el modelo devuelve la probabilidad de cada clase, si total = 13, hubiera devuelto “el reparto” de esos 13 individuos en los 4 grupos
DT::datatable(df_pintar %>%
sample_n(30) %>%
select(edad_cat, valor_cliente, .category, .value))Añadir las 12000 predicciones por fila ya “sólo” nos deja unos 2 millones de filas
dim(df_pintar)## [1] 2400000 9Pintemos
Por ejemplo si queremos ver las estimaciones que le da según la edad podemos ver la distribución posteriori de la probabilidad de cada segmento condicionada a cada grupo de edad.
Salen distribuciones con varias modas debido a la variable valor_cliente que no estamos representando
df_pintar %>%
ggplot(aes(x=.value, y = edad_cat, fill = .category)
) +
geom_density_ridges(scale = 0.8, rel_min_height = 0.01, alpha=.4) +
scale_fill_viridis_d(option = "B") +
theme_ridges() 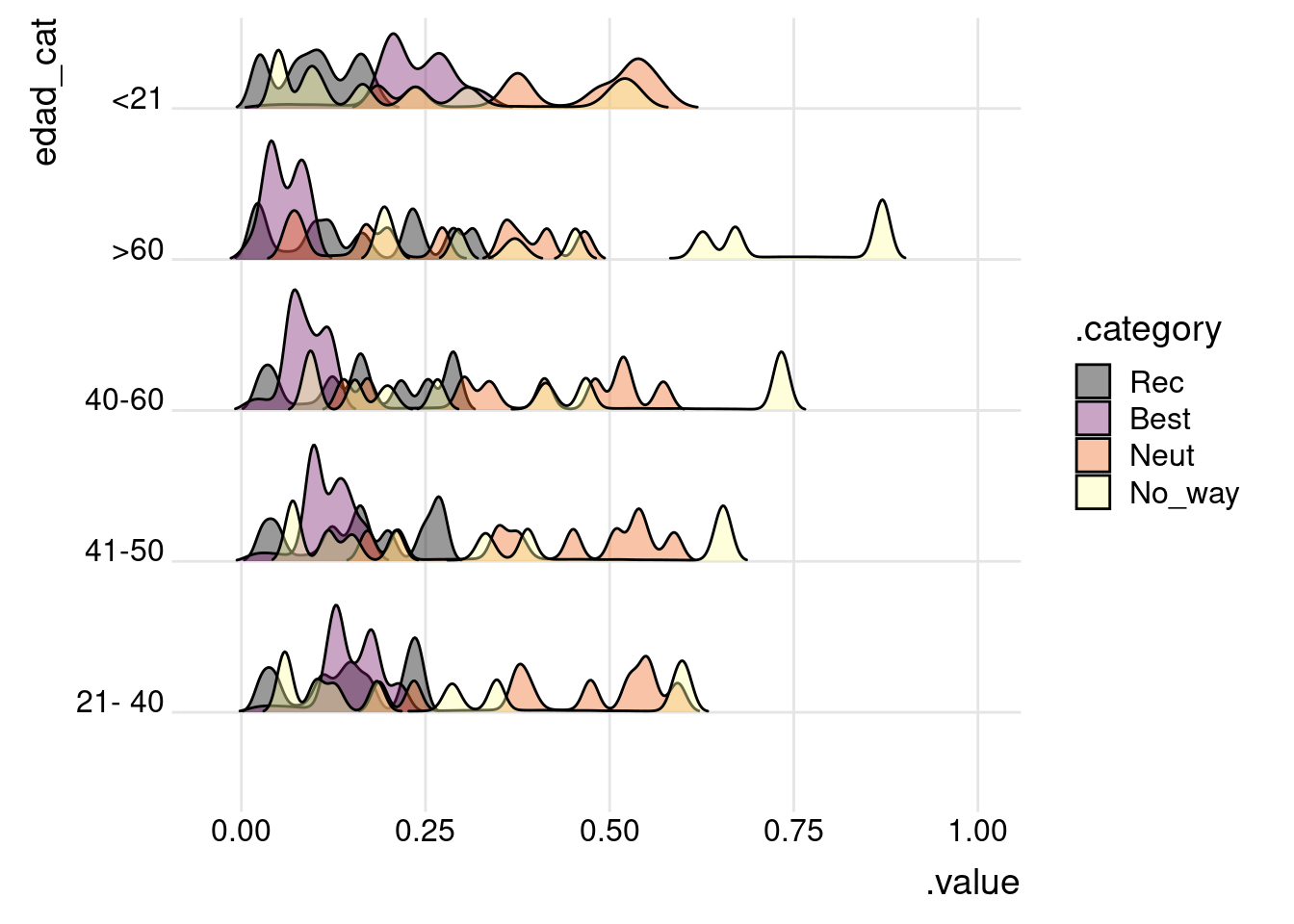
Si vemos la posteriori para los clientes de mayor valor. Se ve claramente que a menor edad mayor probabilidad de pertenecer al segmento “Best” , mientras que a mayor edad es mucho más probabilidad del segmento “No_way”.
df_pintar %>%
filter(valor_cliente == 0) %>%
ggplot(aes(x=.value, y = edad_cat, fill = .category)
) +
geom_density_ridges(scale = 1.5, rel_min_height = 0.01, alpha=.4) +
scale_fill_viridis_d(option = "B") +
theme_ridges() +
labs(title = "Cliente valor: 0")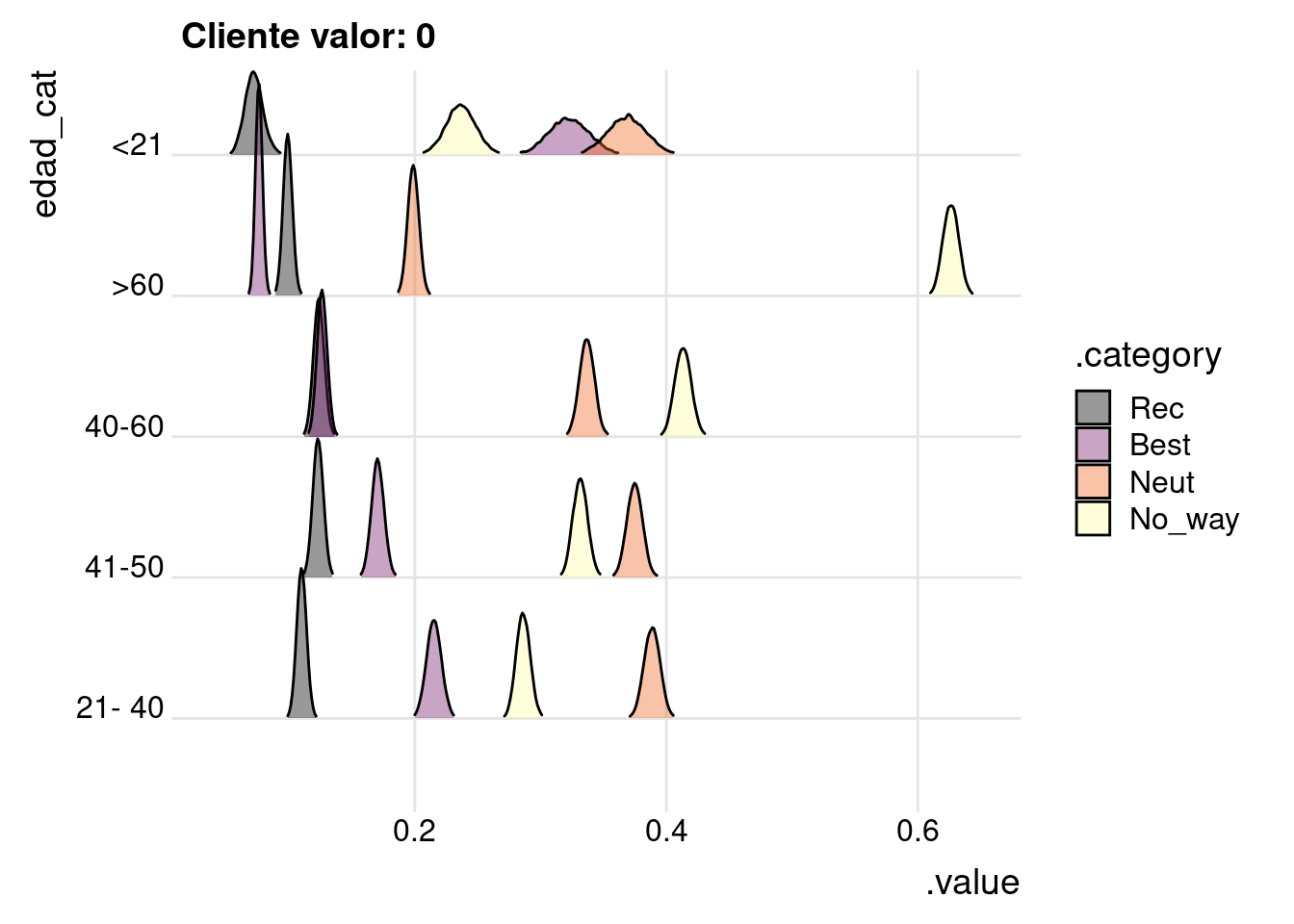
Teniendo toda la distribución podemos ver los resultados desde otro punto de vista. Por ejemplo, ver las probabilidades para los menores de 21.
df_pintar %>%
filter(edad_cat %in% c("<21")) %>%
ggplot(aes(x=.value, y = valor_cliente, fill = .category)
) +
geom_density_ridges(scale = 3, rel_min_height = 0.01, alpha=.4) +
scale_fill_viridis_d(option = "B") +
theme_ridges() +
labs(title = "Clientes menores de 21\n Probabilidades estimadas")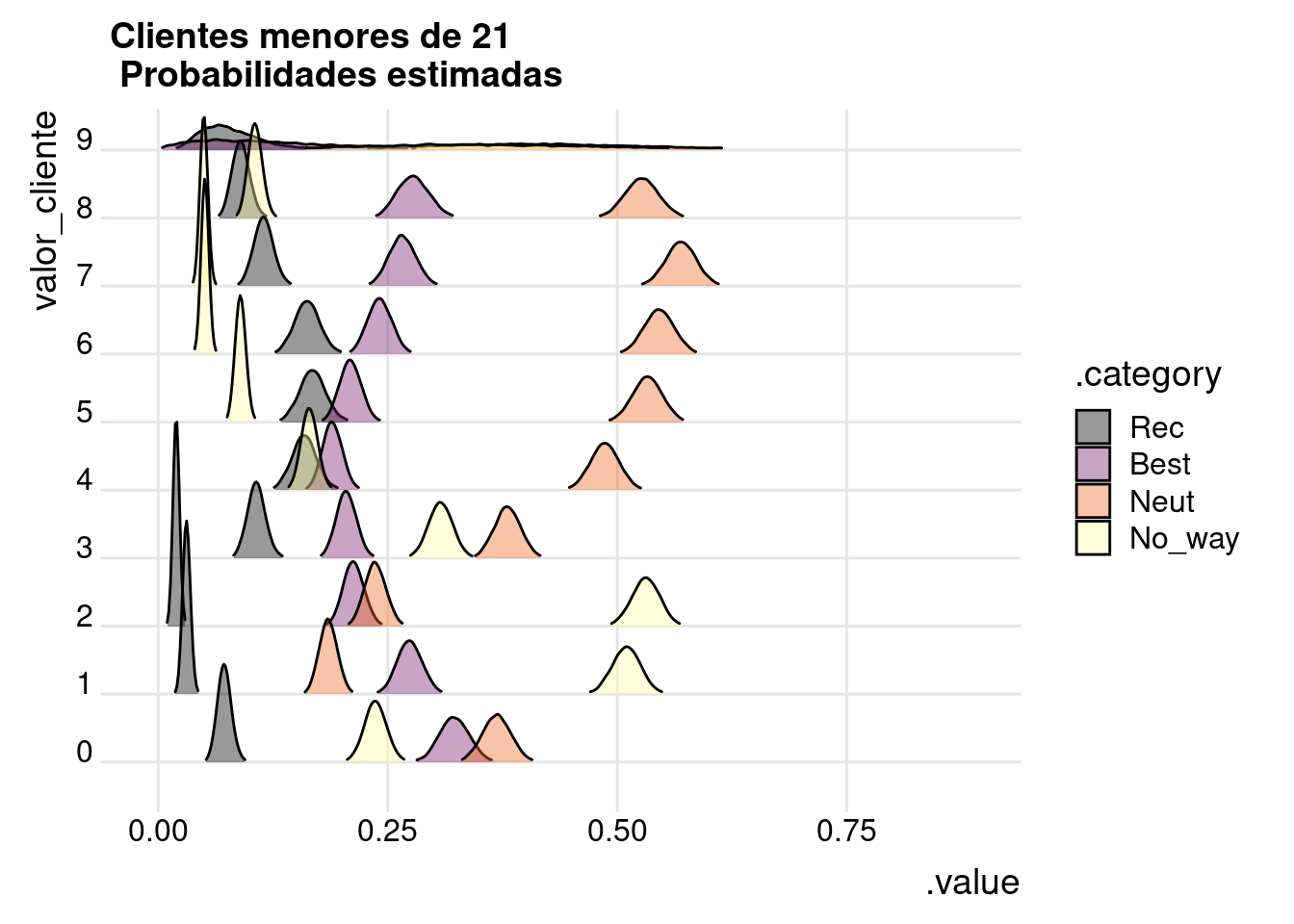
En fin, que se puede hacer estadística bayesiana aún con grandes volúmenes de datos, si te conviertes en lo que mi amigo Antonio llama un “artesano del dato”.
Feliz semana