Después del último post llega el momento de ver si se puede sacar algo interesante del texto. Ya aviso ( y avisé) de que no tengo mucha idea de análisis de texto, por lo que esto es sólo un pequeño ejercicio que he hecho. El csv con el texto de los subtítulos para 2020 lo tenéis en este enlace.
Vamos al lío
library(tidyverse)
root_directory = "~/canadasreche@gmail.com/public/proyecto_cachitos/"
anno <- "2020"Leemos el csv. Uso DT y así podéis ver todos los datos o buscar cosas, por ejemplo Ayuso o pandemia en el cuadro de búsqueda.
subtitulos_proces <- read_csv(str_glue("{root_directory}{anno}_txt_unido.csv"))##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## name = col_double(),
## n_fichero = col_character(),
## n_caracteres = col_double(),
## texto = col_character(),
## distancia = col_double()
## )subtitulos_proces %>%
select(texto, n_fichero, n_caracteres) %>%
DT::datatable()Oye, pues sólo con esto ya nos valdría ¿no?
Pero veamos un poco algunas cosas que podrían hacerse, por ejemplo quitar stopwords. Esto es tan sencillo como tener una lista de palabras que queremos quitar del texto, puede ser nuestra particular, que nos hayamos bajado de algún sitio o que estén disponibles en algún lado
to_remove <- c(tm::stopwords("es"),
"110", "4","1","2","7","10","0","ñ","of",
"5","á","i","the","3", "n", "p",
"ee","uu","mm","ema", "zz",
"wr","wop","wy","x","xi","xl","xt",
"xte","yí", "your", "si")
head(to_remove, 40)## [1] "de" "la" "que" "el" "en" "y" "a"
## [8] "los" "del" "se" "las" "por" "un" "para"
## [15] "con" "no" "una" "su" "al" "lo" "como"
## [22] "más" "pero" "sus" "le" "ya" "o" "este"
## [29] "sí" "porque" "esta" "entre" "cuando" "muy" "sin"
## [36] "sobre" "también" "me" "hasta" "hay"Pero en nuestros datos, las palabras no están separadas, tendríamos que separarlas y luego quitar las que no queremos. Para eso voy a utilizar la librería tidytext de Julia Silge y David Robinson, que nos permite hacer varias cosas relacionadas con análisis de texto.
library(tidytext)
# Con unnest token pasamos a un dataframe qeu tiene tantas filas como palabras
print(str_glue("Filas datos originales: {tally(subtitulos_proces)}"))## Filas datos originales: 541subtitulos_proces_one_word <- subtitulos_proces %>%
unnest_tokens(input = texto,
output = word) %>%
filter(! word %in% to_remove) %>% # quito palabras de la lista
filter(nchar(word)>1) # Nos quedamos con palabras que tengan más de un cáracter
print(str_glue("Filas datos tokenizado: {tally(subtitulos_proces_one_word)}"))## Filas datos tokenizado: 3688subtitulos_proces_one_word %>%
select(name,n_fichero,word, n_caracteres)## # A tibble: 3,688 x 4
## name n_fichero word n_caracteres
## <dbl> <chr> <chr> <dbl>
## 1 14 00000014.jpg.subtitulo.tif.txt después 92
## 2 14 00000014.jpg.subtitulo.tif.txt añito 92
## 3 14 00000014.jpg.subtitulo.tif.txt pasado 92
## 4 14 00000014.jpg.subtitulo.tif.txt aman 92
## 5 14 00000014.jpg.subtitulo.tif.txt consuela 92
## 6 14 00000014.jpg.subtitulo.tif.txt quiere 92
## 7 15 00000015.jpg.subtitulo.tif.txt viendo 62
## 8 15 00000015.jpg.subtitulo.tif.txt actitud 62
## 9 15 00000015.jpg.subtitulo.tif.txt público 62
## 10 15 00000015.jpg.subtitulo.tif.txt actuación 62
## # … with 3,678 more rowsUna cosa simple que podemos hacer es contar palabras, y vemos que lo que más se repite es canción, obvio
palabras_ordenadas <- subtitulos_proces_one_word %>%
group_by(word) %>%
summarise(veces = n()) %>%
arrange(desc(veces))
palabras_ordenadas %>%
slice(1:20) %>%
ggplot(aes(x = reorder(word, veces), y = veces)) +
geom_col(show.legend = FALSE) +
ylab("veces") +
xlab("") +
coord_flip() +
theme_bw()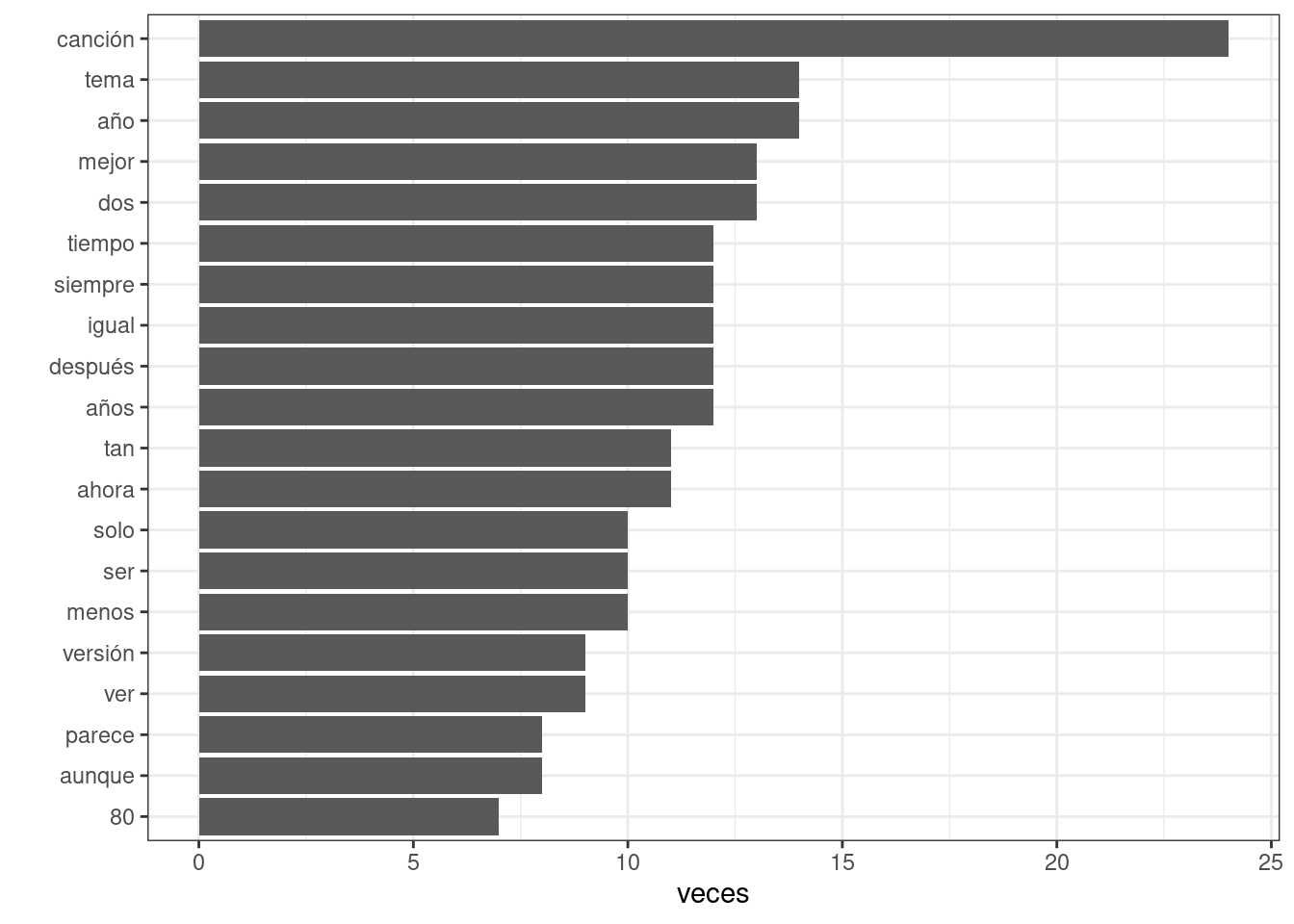
O pintarlas en plan nube de palabras.
library(wordcloud)## Loading required package: RColorBrewerpal <- brewer.pal(8,"Dark2")
subtitulos_proces_one_word %>%
group_by(word) %>%
count() %>%
with(wordcloud(word, n, random.order = FALSE, max.words = 80, colors=pal)) 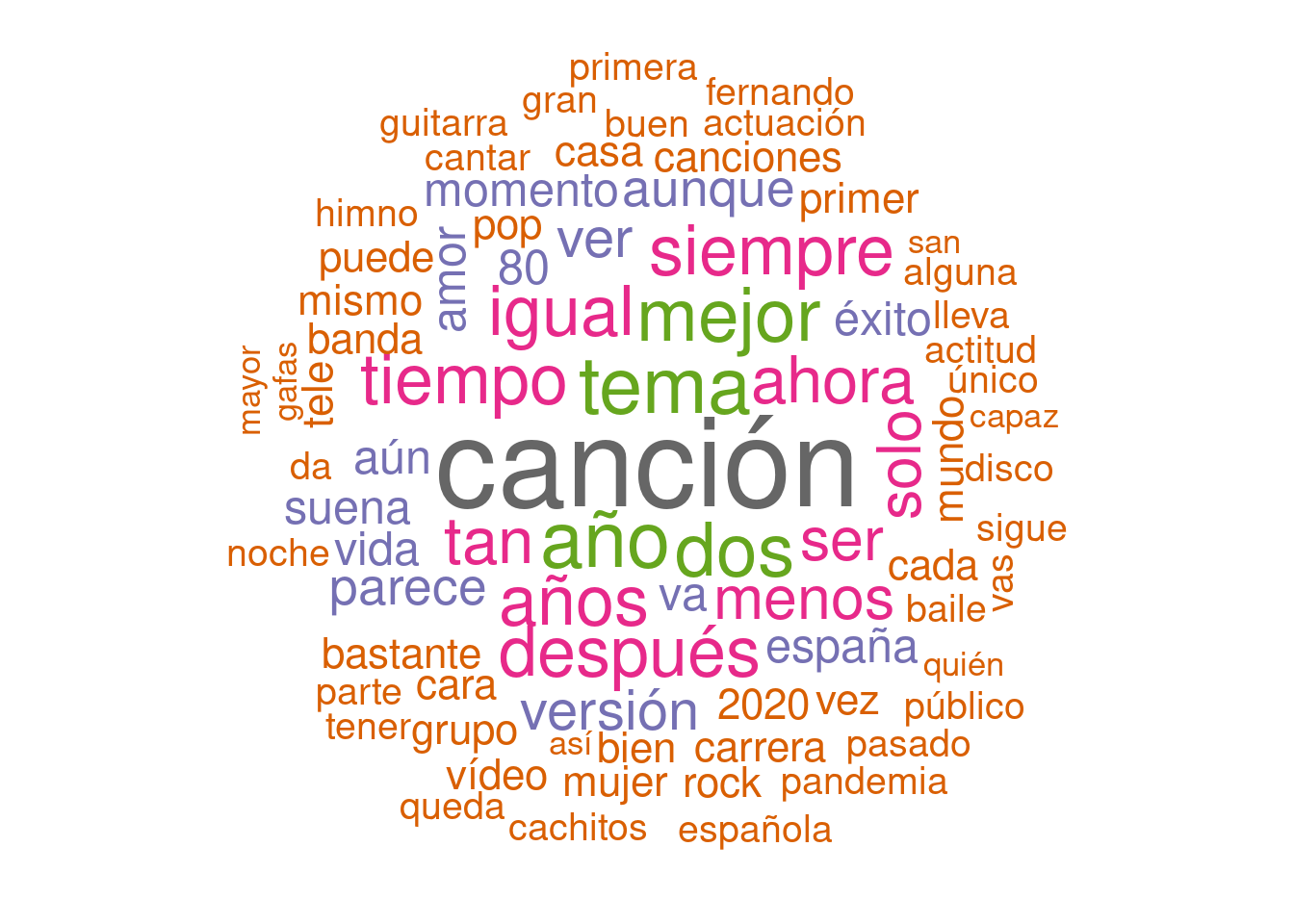
Pues una vez que tenemos las palabras de cada subtítulo separadas podemos buscar palabras polémicas, aunque antes al usar la librería DT ya podíamos buscar, veamos como sería con el código.
Creamos lista de palabras a buscar.
palabras_1 <- c("monarca","pp","vox","rey","coron","zarzuela",
"prisión", "democracia", "abascal","casado",
"ultra","ciudada", "oposición","derech",
"podem","sanchez","iglesias","errejon","izquier",
"gobierno","illa","redondo","ivan","celaa",
"guardia","príncipe","principe","ayuso",
"tezanos","cis","republic", "simon", "pandem","lazo",
"toled","alber","fach", "zarzu", "democr","vicepre", "minist",
"irene","montero","almeida")Construimos una regex para que encuentre las palabras que empiecen así.
(exp_regx <- paste0("^",paste(palabras_1, collapse = "|^")))## [1] "^monarca|^pp|^vox|^rey|^coron|^zarzuela|^prisión|^democracia|^abascal|^casado|^ultra|^ciudada|^oposición|^derech|^podem|^sanchez|^iglesias|^errejon|^izquier|^gobierno|^illa|^redondo|^ivan|^celaa|^guardia|^príncipe|^principe|^ayuso|^tezanos|^cis|^republic|^simon|^pandem|^lazo|^toled|^alber|^fach|^zarzu|^democr|^vicepre|^minist|^irene|^montero|^almeida"Y nos creamos una variable que valga TRUE cuando suceda esto
subtitulos_proces_one_word <- subtitulos_proces_one_word %>%
mutate(polemica= str_detect(word, exp_regx))
subtitulos_proces_one_word %>%
filter(polemica) %>%
select(name, word, n_fichero) ## # A tibble: 38 x 3
## name word n_fichero
## <dbl> <chr> <chr>
## 1 193 gobierno 00000193.jpg.subtitulo.tif.txt
## 2 193 pandemia 00000193.jpg.subtitulo.tif.txt
## 3 222 montero 00000222.jpg.subtitulo.tif.txt
## 4 222 montero 00000222.jpg.subtitulo.tif.txt
## 5 300 illa 00000300.jpg.subtitulo.tif.txt
## 6 308 reyes 00000308.jpg.subtitulo.tif.txt
## 7 308 pandemia 00000308.jpg.subtitulo.tif.txt
## 8 343 prisión 00000343.jpg.subtitulo.tif.txt
## 9 357 zarzuela 00000357.jpg.subtitulo.tif.txt
## 10 363 abascal 00000363.jpg.subtitulo.tif.txt
## # … with 28 more rowsPodríamos ver el texto de los subtítulos, para eso, nos quedamos con un identificador, como el nombre del fichero txt, que nos servirá luego para leer la imagen.
Pues en realidad tenemos sólo 32 subtítulos polémicos de los de alrededor de 540 que hay, no parecen muchos.
subtitulos_polemicos <- subtitulos_proces_one_word %>%
filter(polemica) %>%
pull(n_fichero) %>%
unique()
subtitulos_polemicos## [1] "00000193.jpg.subtitulo.tif.txt" "00000222.jpg.subtitulo.tif.txt"
## [3] "00000300.jpg.subtitulo.tif.txt" "00000308.jpg.subtitulo.tif.txt"
## [5] "00000343.jpg.subtitulo.tif.txt" "00000357.jpg.subtitulo.tif.txt"
## [7] "00000363.jpg.subtitulo.tif.txt" "00000471.jpg.subtitulo.tif.txt"
## [9] "00000508.jpg.subtitulo.tif.txt" "00000510.jpg.subtitulo.tif.txt"
## [11] "00000531.jpg.subtitulo.tif.txt" "00000551.jpg.subtitulo.tif.txt"
## [13] "00000557.jpg.subtitulo.tif.txt" "00000598.jpg.subtitulo.tif.txt"
## [15] "00000632.jpg.subtitulo.tif.txt" "00000638.jpg.subtitulo.tif.txt"
## [17] "00000640.jpg.subtitulo.tif.txt" "00000670.jpg.subtitulo.tif.txt"
## [19] "00000702.jpg.subtitulo.tif.txt" "00000760.jpg.subtitulo.tif.txt"
## [21] "00000830.jpg.subtitulo.tif.txt" "00000893.jpg.subtitulo.tif.txt"
## [23] "00000896.jpg.subtitulo.tif.txt" "00000948.jpg.subtitulo.tif.txt"
## [25] "00001010.jpg.subtitulo.tif.txt" "00001037.jpg.subtitulo.tif.txt"
## [27] "00001057.jpg.subtitulo.tif.txt" "00001115.jpg.subtitulo.tif.txt"
## [29] "00001122.jpg.subtitulo.tif.txt" "00001142.jpg.subtitulo.tif.txt"
## [31] "00001143.jpg.subtitulo.tif.txt" "00001229.jpg.subtitulo.tif.txt"Vemos el texto mirando en el dataframe antes de separar las palabras. La verdad es que hay que reconocer que son bastante ingeniosos, jejje. Aunque hay algún falso positivo como el de “la carta a los reyes magos de la post pandemia 4 pan alegría y ertes” y alguno más. La verdad es que un pelín de sesgo se les nota, de meterse más con la oposición que con el gobierno comparado con lo del año pasado (probad)
(texto_polemicos <- subtitulos_proces %>%
filter(n_fichero %in% subtitulos_polemicos) %>%
arrange(n_fichero) %>%
pull(texto))## [1] "esta fue la lógica del gobierno al ceder la responsabilidad 4 del control de la pandemia a las comunidades autónomas"
## [2] "ante montero y post montero"
## [3] "ahí parecían formales pero ya cerraban más bares que salvador illa"
## [4] "la carta a los reyes magos de la post pandemia 4 pan alegría y ertes"
## [5] "cintas amarillas gente en prisión pasó hace 3 años si eso ponéis vosotros el rótulo y ya os llama marchena"
## [6] "canción romántica rock zarzuela yeyé versátil como bowie pero más conservador en cuestión de peinados"
## [7] "el único elemento rojo en un entorno blanco paco es el bote de pimentón en el despacho de santiago abascal"
## [8] "no has querido ver el vídeo de las vacaciones de tu cuñado y nosotros te estamos colando las de julio iglesias"
## [9] "príncipe gitano ditah"
## [10] "es increíble la que se lía en barcelona cada vez que la pisa un príncipe"
## [11] "según un informe de la guardia civil la culpa fue del cha cha chá y de la mani del 8 m"
## [12] "suele decirse que una de las mejores cosas de nuestro país es su luz no podemos estar más de acuerdo"
## [13] "esta es la música que sonaba de fondo cuando casado se hizo la foto ante el espejo del baño"
## [14] "nos ahorraremos decir que era el rey de la rumba porque p este año todo lo que lleva corona ha ido regular"
## [15] "o ortega e isabel montero cre la hiedra"
## [16] "aprovechamos para celebrar la llegada de la primera mujer a la vicepresidencia de los estados unidos camela harri"
## [17] "su mayor éxito lo compuso miguel angel cabrera el teclista de la derecha que está currándose una tendi"
## [18] "esto les puso ayuso a los albañiles de su hospital por megafonía y ni aún así oye"
## [19] "este es su mayor éxito y se basó en un libro sobre elvis tenemos fe en que esté vivo y reclame los derechos"
## [20] "cuando pienses que la pandemia te ha afectado recuerda que a geo le ha robado la inspiración del 100 de sus temas"
## [21] "la pandemia interrumpió su gira de 40 aniversario carlos segarra al rock and roll con las dos manos"
## [22] "en ella esos colores conjuntan mejor que en el gobierno de coalición"
## [23] "3 la fernando simón del pp pop internacional"
## [24] "mucho antes de su coaching durante la pandemia p karina ya lanzaba mensajes de taza de desayuno"
## [25] "si aute no fue capaz de entender el mundo quiénes somos nosotros para creer que podemos"
## [26] "hay que tener mucho cuidado con las fiestas te despistas un momento y la ultraderecha se te cuela en la de la democracia"
## [27] "iván redondo está apuntando todo para el próximo discurso sobre la nueva normalidad"
## [28] "on ppy children"
## [29] "el baile reproduce la rara habilidad de pp y vox darse la mano y la espalda al mismo tiempo ll"
## [30] "en la zarzuela ha sonado más la de se fue"
## [31] "el currículum amoroso de laura pausini tiene más abandonos que las listas de ciudadanos"
## [32] "seria la versión latina del compañero de mimos que propuso el gobierno belga en el confinamiento y qué mimos"Podemos ver las imágenes
(polemica_fotogramas <- unique(substr(subtitulos_polemicos, 1,12)))## [1] "00000193.jpg" "00000222.jpg" "00000300.jpg" "00000308.jpg" "00000343.jpg"
## [6] "00000357.jpg" "00000363.jpg" "00000471.jpg" "00000508.jpg" "00000510.jpg"
## [11] "00000531.jpg" "00000551.jpg" "00000557.jpg" "00000598.jpg" "00000632.jpg"
## [16] "00000638.jpg" "00000640.jpg" "00000670.jpg" "00000702.jpg" "00000760.jpg"
## [21] "00000830.jpg" "00000893.jpg" "00000896.jpg" "00000948.jpg" "00001010.jpg"
## [26] "00001037.jpg" "00001057.jpg" "00001115.jpg" "00001122.jpg" "00001142.jpg"
## [31] "00001143.jpg" "00001229.jpg"polemica_fotogramas_full <- paste0(str_glue("{root_directory}video/{anno}_jpg/"), polemica_fotogramas)
subtitulos_polemicos_full <- paste0(polemica_fotogramas_full,".subtitulo.tif")Y ahora utilizando la librería magick en R y un poco de programación funcional (un simple map), tenemos la imagen leída
library(magick)## Linking to ImageMagick 6.9.10.23
## Enabled features: fontconfig, freetype, fftw, lcms, pango, webp, x11
## Disabled features: cairo, ghostscript, heic, raw, rsvg## Using 12 threadsfotogramas_polemicos_img <- map(polemica_fotogramas_full, image_read)
subtitulos_polemicos_img <- map(subtitulos_polemicos_full, image_read)subtitulos_polemicos_img[[31]]
fotogramas_polemicos_img[[31]]
Uhmm, la verdad es que podría montar un shiny que dada una palabra mostrara el fotograma, sería sencillo.
O podriamos ponerlos todos juntos, la verdad es que magick mola
lista_fotogram_polemicos <- map(fotogramas_polemicos_img, grid::rasterGrob)
gridExtra::grid.arrange(grobs=lista_fotogram_polemicos)
Realmente creo que falta mucha limpieza del texto, por lo que me cuentan los que saben el trabajo de verdad en texto es ese.
Más cositas que se me ocurrieron hacer, por ejemplo ver ngramas. Para eso puedo recomponer los comentarios a partir de subtitulos_proces_one_word que ya tienen palabras quitadas.
Fijaros en este código
n = 4
subtitulos_proces_one_word %>%
group_by(name, n_fichero) %>%
nest(data = word) %>%
mutate(texto = map(data, unlist),
texto = map_chr(texto, paste, collapse = " ")) %>%
unnest_tokens(input = texto,
output = ngramas,token = "ngrams", n = n) %>%
ungroup() %>%
select(n_fichero,ngramas) %>%
filter(nchar(ngramas)>2) %>%
group_by(ngramas) %>%
summarise(veces = n()) %>%
arrange(desc(veces)) %>%
top_n(20, veces)Vamos por cachos, valga la redundancia.
A partir de las palabras puedo recomponer el subtítulo original porque tengo el identificador, para eso la función nest es muy útil. Yo a veces utilizo esta función para almacenar en un elemento de una columna un dataframe enteror.
subtitulos_proces_one_word %>%
group_by(name, n_fichero) %>%
nest(data = word) %>%
select(name, data)## Adding missing grouping variables: `n_fichero`## # A tibble: 573 x 3
## # Groups: name, n_fichero [541]
## n_fichero name data
## <chr> <dbl> <list>
## 1 00000014.jpg.subtitulo.tif.txt 14 <tibble [6 × 1]>
## 2 00000015.jpg.subtitulo.tif.txt 15 <tibble [4 × 1]>
## 3 00000016.jpg.subtitulo.tif.txt 16 <tibble [6 × 1]>
## 4 00000019.jpg.subtitulo.tif.txt 19 <tibble [4 × 1]>
## 5 00000020.jpg.subtitulo.tif.txt 20 <tibble [12 × 1]>
## 6 00000021.jpg.subtitulo.tif.txt 21 <tibble [10 × 1]>
## 7 00000025.jpg.subtitulo.tif.txt 25 <tibble [4 × 1]>
## 8 00000026.jpg.subtitulo.tif.txt 26 <tibble [6 × 1]>
## 9 00000027.jpg.subtitulo.tif.txt 27 <tibble [8 × 1]>
## 10 00000031.jpg.subtitulo.tif.txt 31 <tibble [9 × 1]>
## # … with 563 more rowsEn este caso para cada name y n_fichero ha generado un tibble, de una sola columna y de tantas filas como palabras.
subtitulos_proces_one_word %>%
group_by(name, n_fichero) %>%
nest(data = word) %>%
ungroup() %>%
slice(1:2) %>%
pull(data)## [[1]]
## # A tibble: 6 x 1
## word
## <chr>
## 1 después
## 2 añito
## 3 pasado
## 4 aman
## 5 consuela
## 6 quiere
##
## [[2]]
## # A tibble: 4 x 1
## word
## <chr>
## 1 viendo
## 2 actitud
## 3 público
## 4 actuaciónEl resto de funciones es convertir esa lista en vector de caracteres, juntar las palabras y separar por espacios, extraer los n_gramas de tamaño 4 palabras, contar cuántas veces aparece cada n_grama y ver los 20 más frecuentes. Con esto lo que se puede detectar son subtítulos que aparezcan duplicados y se nos hayan escapado por la distancia de strings que usamos en el post anterior
n = 4
subtitulos_proces_one_word %>%
group_by(name, n_fichero) %>%
nest(data = word) %>%
mutate(texto = map(data, unlist),
texto = map_chr(texto, paste, collapse = " ")) %>%
unnest_tokens(input = texto,
output = ngramas,token = "ngrams", n = n) %>%
ungroup() %>%
select(n_fichero,ngramas) %>%
filter(nchar(ngramas)>2) %>%
group_by(ngramas) %>%
summarise(veces = n()) %>%
arrange(desc(veces)) %>%
top_n(20, veces)## # A tibble: 2,079 x 2
## ngramas veces
## <chr> <int>
## 1 alto nunca llegó ser 2
## 2 aunque fama saturó supo 2
## 3 aute capaz entender mundo 2
## 4 después dos décadas elegido 2
## 5 fama saturó supo volver 2
## 6 justo reconocer submarino beatles 2
## 7 llegó ser remero harvard 2
## 8 mujer tan valiente después 2
## 9 nunca llegó ser remero 2
## 10 reconocer submarino beatles menos 2
## # … with 2,069 more rowsEn el próximo post veremos algo más, que estoy “cansao de to el día”.
comments powered by Disqus