En el post anterior vimos como extraer 1 de cada n fotogramas de un video, recortar una zona en concreto y pasarle un software de reconocimiento óptico de caracteres para tener el texto. En esta parte vamos a ver como leer esos ficheros de texto y también una de las formas de quitar subtítulos duplicados. Para eso vamos a utilizar R. Vamos al lío.
Ejecuto el script extract_subtitles.sh del post anterior de la siguiente forma.
./extract_subtitles.sh 2020
./extract_subtitles.sh 2019Se baja el video desde alacarta, recorta los subtítulos y obtiene el texto. La estructura de directorios que me crea en dónde le haya dicho que es el root_directory es
╰─ $ ▶ tree -d
.
├── 2019_txt
├── 2020_txt
└── video
├── 2019_jpg
└── 2020_jpg
Dónde en video tenemos los dos videos en mp4, y los directorios con los fotogramas originales junto con los subtítulos, y en los directorios anno_txt cada uno de los ficheros de texto correspondientes a los fotogramas.
╰─ $ ▶ ll 2020_txt | head -n 20
total 5456
drwxrwxr-x 2 jose jose 77824 ene 11 20:51 ./
drwxrwxr-x 8 jose jose 4096 ene 13 19:41 ../
-rw-rw-r-- 1 jose jose 1 ene 4 13:07 00000001.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 1 ene 4 13:06 00000002.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 1 ene 4 13:07 00000003.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 1 ene 4 13:08 00000004.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 3 ene 4 13:07 00000005.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 3 ene 4 13:07 00000006.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 3 ene 4 13:07 00000007.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 3 ene 4 13:06 00000008.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 1 ene 4 13:07 00000009.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 3 ene 4 13:08 00000010.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 1 ene 4 13:08 00000011.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 6 ene 4 13:07 00000012.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 24 ene 4 13:06 00000013.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 94 ene 4 13:07 00000014.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 65 ene 4 13:07 00000015.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 93 ene 4 13:06 00000016.jpg.subtitulo.tif.txt
-rw-rw-r-- 1 jose jose 1 ene 4 13:06 00000017.jpg.subtitulo.tif.txt
╰─ $ ▶ ll 2020_txt | wc -l
1347
Y vemos que hay 1347 ficheros txt, y algunos muy pequeños (los que no tienen texto)
Veamos el 00000016.jpg.subtitulo.tif.txt
╰─ $ ▶ cat 2020_txt/00000016.jpg.subtitulo.tif.txt
Viendo la actitud del público, más que una actuación
esto es una sesión de coaching.Pues vamos a leerlos todos usando R.
library(tidyverse)## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.3 ✓ purrr 0.3.4
## ✓ tibble 3.0.4 ✓ dplyr 1.0.2
## ✓ tidyr 1.1.2 ✓ stringr 1.4.0
## ✓ readr 1.4.0 ✓ forcats 0.5.0## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()root_directory = "~/canadasreche@gmail.com/public/proyecto_cachitos/"
anno <- "2020"
# Construims un data frame con los nombrs de los ficheros
nombre_ficheros <- list.files(path = str_glue("{root_directory}{anno}_txt/")) %>%
enframe() %>%
rename(n_fichero = value)
nombre_ficheros## # A tibble: 1,344 x 2
## name n_fichero
## <int> <chr>
## 1 1 00000001.jpg.subtitulo.tif.txt
## 2 2 00000002.jpg.subtitulo.tif.txt
## 3 3 00000003.jpg.subtitulo.tif.txt
## 4 4 00000004.jpg.subtitulo.tif.txt
## 5 5 00000005.jpg.subtitulo.tif.txt
## 6 6 00000006.jpg.subtitulo.tif.txt
## 7 7 00000007.jpg.subtitulo.tif.txt
## 8 8 00000008.jpg.subtitulo.tif.txt
## 9 9 00000009.jpg.subtitulo.tif.txt
## 10 10 00000010.jpg.subtitulo.tif.txt
## # … with 1,334 more rowsAhora los podemos leer en orden
subtitulos <- list.files(path = str_glue("{root_directory}{anno}_txt/"),
pattern = "*.txt", full.names = TRUE) %>%
map(~read_file(.)) %>%
enframe() %>%
# hacemos el join con el dataframe anterior para tener el nombre del fichero original
left_join(nombre_ficheros)## Joining, by = "name"glimpse(subtitulos)## Rows: 1,344
## Columns: 3
## $ name <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, …
## $ value <list> ["\f", "\f", "\f", "\f", " \n\f", " \n\f", " \n\f", " \n\f…
## $ n_fichero <chr> "00000001.jpg.subtitulo.tif.txt", "00000002.jpg.subtitulo.t…subtitulos## # A tibble: 1,344 x 3
## name value n_fichero
## <int> <list> <chr>
## 1 1 <chr [1]> 00000001.jpg.subtitulo.tif.txt
## 2 2 <chr [1]> 00000002.jpg.subtitulo.tif.txt
## 3 3 <chr [1]> 00000003.jpg.subtitulo.tif.txt
## 4 4 <chr [1]> 00000004.jpg.subtitulo.tif.txt
## 5 5 <chr [1]> 00000005.jpg.subtitulo.tif.txt
## 6 6 <chr [1]> 00000006.jpg.subtitulo.tif.txt
## 7 7 <chr [1]> 00000007.jpg.subtitulo.tif.txt
## 8 8 <chr [1]> 00000008.jpg.subtitulo.tif.txt
## 9 9 <chr [1]> 00000009.jpg.subtitulo.tif.txt
## 10 10 <chr [1]> 00000010.jpg.subtitulo.tif.txt
## # … with 1,334 more rowsen n_fichero tenemos el nombre y en value el texto
subtitulos %>%
pull(value) %>%
## usamos `[[` que es el operador para acceder a la lista el que normalemente se usa [[nombre_elemento]]
`[[`(16)## [1] "Viendo la actitud del público, más que una actuación\nesto es una sesión de coaching.\n\n \n\f"# equivalentemente
# subtitulos %>%
# pull(value) %>%
# pluck(16)Como sabemos que hay muchos ficheros sin texto podemos contar letras.
subtitulos <- subtitulos %>%
mutate(n_caracteres = nchar(value))
subtitulos %>%
group_by(n_caracteres) %>%
count()## # A tibble: 127 x 2
## # Groups: n_caracteres [127]
## n_caracteres n
## <int> <int>
## 1 1 480
## 2 3 125
## 3 4 17
## 4 5 7
## 5 6 13
## 6 7 2
## 7 8 7
## 8 9 6
## 9 10 4
## 10 11 5
## # … with 117 more rowssubtitulos %>%
group_by(n_caracteres) %>%
count() %>%
ggplot(aes(x = n_caracteres, y = n)) +
geom_col()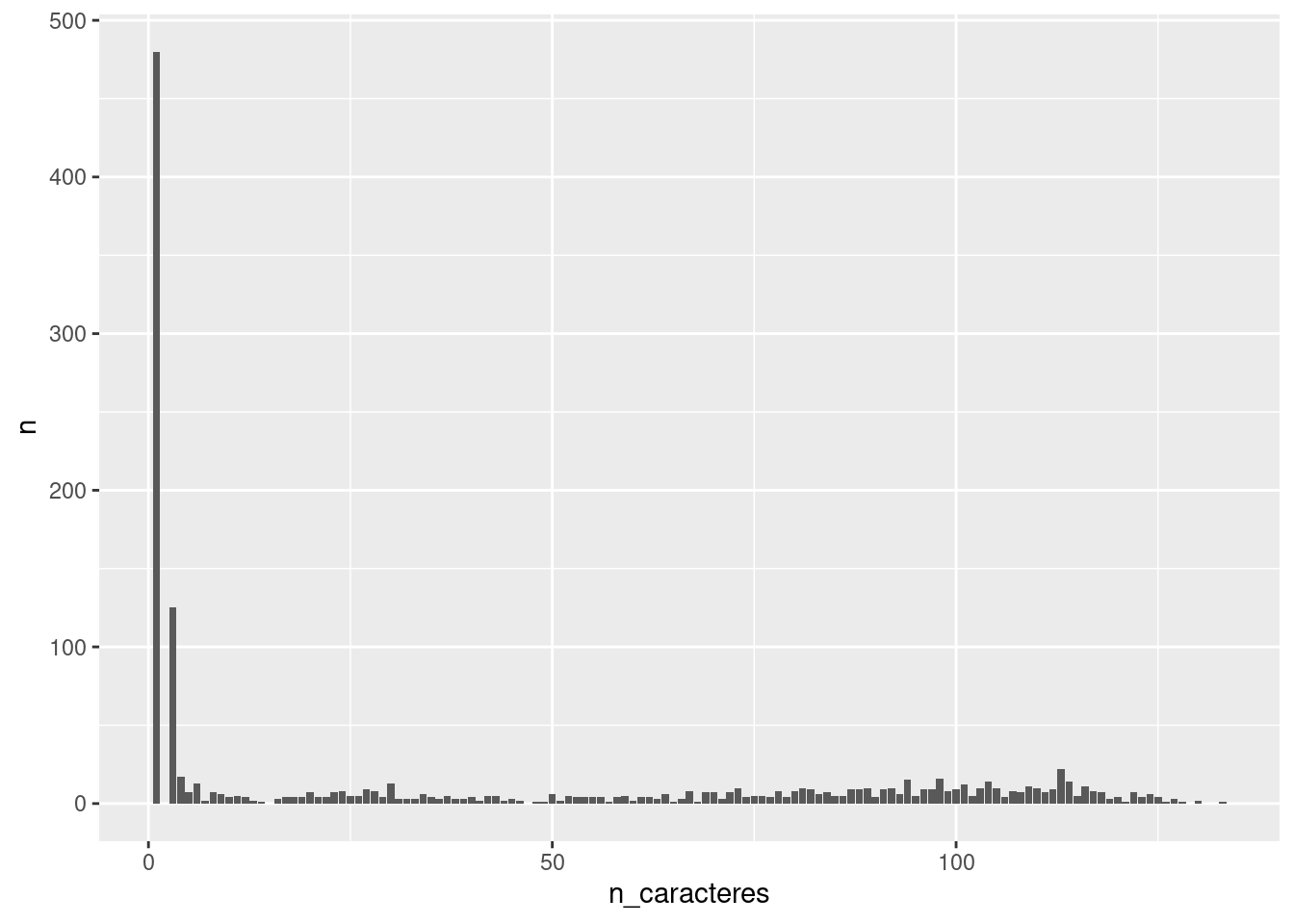
Y vemos que hay muchos subtitulos con pocos caracteres. Si vemos por ejemplo los que tienen 8 caracteres
subtitulos %>%
filter(n_caracteres ==8) %>%
pull(value)## [[1]]
## [1] "LEN As\n\f"
##
## [[2]]
## [1] "pro\n\nÑ\n\f"
##
## [[3]]
## [1] "ñ Xd a\n\f"
##
## [[4]]
## [1] "/ EI\nE\n\f"
##
## [[5]]
## [1] "TOY ES\n\f"
##
## [[6]]
## [1] "110\n\ny\n\f"
##
## [[7]]
## [1] "steria\n\f"Que se corresponden con haber pillado parte no del subtítulo sino del nombre de la actuación
subtitulos %>%
filter(n_caracteres ==8)## # A tibble: 7 x 4
## name value n_fichero n_caracteres
## <int> <list> <chr> <int>
## 1 207 <chr [1]> 00000207.jpg.subtitulo.tif.txt 8
## 2 252 <chr [1]> 00000252.jpg.subtitulo.tif.txt 8
## 3 321 <chr [1]> 00000321.jpg.subtitulo.tif.txt 8
## 4 339 <chr [1]> 00000339.jpg.subtitulo.tif.txt 8
## 5 442 <chr [1]> 00000442.jpg.subtitulo.tif.txt 8
## 6 494 <chr [1]> 00000494.jpg.subtitulo.tif.txt 8
## 7 722 <chr [1]> 00000722.jpg.subtitulo.tif.txt 8Usando la librería magick en R que permite usar imagemagick en R, ver post de Raúl Vaquerizo y su homenaje a Sean Connery, podemos ver el fotgrama correspondiente
library(magick)## Linking to ImageMagick 6.9.10.23
## Enabled features: fontconfig, freetype, fftw, lcms, pango, webp, x11
## Disabled features: cairo, ghostscript, rsvg## Using 12 threads(directorio_imagenes <- str_glue("{root_directory}video/{anno}_jpg/"))## ~/canadasreche@gmail.com/public/proyecto_cachitos/video/2020_jpg/image_read(str_glue("{directorio_imagenes}00000207.jpg"))
También podemos ver hasta cuando pasa eso, por ejemplo si vemos subtítulos con 18 caracteres
subtitulos %>%
filter(n_caracteres ==18) %>%
pull(value)## [[1]]
## [1] " \n\nA BAEZA\n\n ———\n\f"
##
## [[2]]
## [1] "Descanse en Pau.\n\f"
##
## [[3]]
## [1] "VEL y BIMBA BOSÉ\n\f"
##
## [[4]]
## [1] "IIS >>\n\npd.\ndd >\n\f"Vemos que también pasa, pero ya vamos pillando rótulos de verdad como el “Descanse en Pau” que pusieron ante una actuación de Pau Donés.
Como vemos hay que hacer limpieza, pero por el momento vamos a quedarnos con los subtítulos con número de caracteres mayor de 17. Esta decisión hace que perdamos algunos subtítulos de verdad, como por ejemplo el conocido “Loco Vox”.
subtitulos <- subtitulos %>%
filter(n_caracteres > 17)
glimpse(subtitulos)## Rows: 664
## Columns: 4
## $ name <int> 13, 14, 15, 16, 19, 20, 21, 22, 25, 26, 27, 31, 32, 33, …
## $ value <list> [" \n\nA BAEZA\n\n ———\n\f", "Después del añito que hem…
## $ n_fichero <chr> "00000013.jpg.subtitulo.tif.txt", "00000014.jpg.subtitul…
## $ n_caracteres <int> 18, 92, 62, 89, 50, 112, 114, 114, 31, 91, 78, 117, 98, …Pues ya hemos pasado de más de 1000 rótulos a 664. Pero sabemos, por el post anterior que hay algunos duplicados.
Con el fin de detectar cuáles están duplicados y aprovechando que están en orden de aparición, podemos hacer utilizar distancias de texto para calcular la distancia de cada subtítulo con el anterior, y si la distancia es pequeña es que es el mismo rótulo.
Primero hacemos una minilimpieza.
string_mini_clean <- function(string){
string <- gsub("?\n|\n", " ", string)
string <- gsub("\r|?\f|=", " ", string)
string <- gsub('“|”|—|>'," ", string)
string <- gsub("[[:punct:][:blank:]]+", " ", string)
string <- tolower(string)
string <- gsub(" ", " ", string)
string <-
return(string)
}
# Haciendo uso de programacion funciona con purrr es muy fácil pasar esta función a cada elemento. y decirle que # el reultado es string con map_chr
subtitulos_proces <- subtitulos %>%
mutate(texto = map_chr(value, string_mini_clean)) %>%
select(-value)
subtitulos_proces %>%
select(texto)## # A tibble: 664 x 1
## texto
## <chr>
## 1 " a baeza "
## 2 "después del añito que hemos pasado quien mm aman 110 se consuela es porque …
## 3 "viendo la actitud del público más que una actuación esto es "
## 4 "viendo la actitud del público más que una actuación esto es una sesión de c…
## 5 " intura y su conjunto conga del jaruco 2 "
## 6 "la última vez que hiciste algo parecido fue en el súper y llevabas 25 rollo…
## 7 " a que produce nostalgia ver a un grupo de españoles p poniéndose de acuerd…
## 8 " a que produce nostalgia ver a un grupo de españoles poniéndose de acuerdo …
## 9 "jno lomas xte conmigo pi "
## 10 "í 7 igual lo que nos ha caído es una maldición india rel y este es el orige…
## # … with 654 more rowsY ya vemos a simple vista que hay algun duplicado. Calculemos ahora la distancia de strings, utilizando la función stringdist de la librería del mismo nombre.
subtitulos_proces %>%
mutate(texto_anterior = lag(texto)) %>%
# calculamos distancias con método lcs (que no me he leído que hace exactamente)
mutate(distancia = stringdist::stringdist(texto, texto_anterior, method = "lcs")) %>%
# veamos algunos elementos
filter(distancia < 10) %>%
arrange(desc(distancia) ) %>%
select(texto, texto_anterior, distancia) %>%
head()## # A tibble: 6 x 3
## texto texto_anterior distancia
## <chr> <chr> <dbl>
## 1 "mn por si no te lo ha dicho a… "a si no te lo ha dicho aún tu cuña… 9
## 2 "por alguna razón a beyoncé le… " zz por alguna razón a beyoncé le … 6
## 3 "asi es como se visten los daf… "asi es como se visten los daft pun… 6
## 4 "la pandemia interrumpió su gi… "la pandemia interrumpió su gira de… 6
## 5 "2 xl en viajes al pasado los … "2 xl en viajes al pasado los 80 co… 6
## 6 "lp parece que a nek le ha pil… "parece que a nek le ha pillado des… 6Y parece que funciona. Así que decido quitar las filas dónde la distancia sea menos que 19 y así eliminar muchos de los duplicados.
subtitulos_proces <- subtitulos_proces %>%
mutate(texto_anterior = lag(texto)) %>%
mutate(distancia = stringdist::stringdist(texto, texto_anterior, method = "lcs")) %>%
filter(distancia > 19) %>%
select(-texto_anterior)
subtitulos_proces %>%
head()## # A tibble: 6 x 5
## name n_fichero n_caracteres texto distancia
## <int> <chr> <int> <chr> <dbl>
## 1 14 00000014.jpg.sub… 92 "después del añito que hemos p… 84
## 2 15 00000015.jpg.sub… 62 "viendo la actitud del público… 89
## 3 16 00000016.jpg.sub… 89 "viendo la actitud del público… 23
## 4 19 00000019.jpg.sub… 50 " intura y su conjunto conga d… 76
## 5 20 00000020.jpg.sub… 112 "la última vez que hiciste alg… 103
## 6 21 00000021.jpg.sub… 114 " a que produce nostalgia ver … 128Y ahora escribimos este dataframe en un csv y será la materia prima para ver qué podemos hacer con esto (para eso requeriré ayuda de algún amigo más ducho en tales artes)
write_csv(subtitulos_proces,
file = str_glue("{root_directory}{anno}_txt_unido.csv"))Y os dejo este csv en este enlace
comments powered by Disqus