En el post anterior se me olvidó comentar que una parte importante es la interpretación.
library(psych)
library(polycor)##
## Attaching package: 'polycor'## The following object is masked from 'package:psych':
##
## polyserialdatos <- readRDS("../../data/science.rds")
cor_poly <- hetcor(datos)## Warning in log(P): Se han producido NaNsres_factorial <- fa(cor_poly$correlations, nfactors = 3, n.obs = nrow(datos))## Loading required namespace: GPArotationdiagram(res_factorial)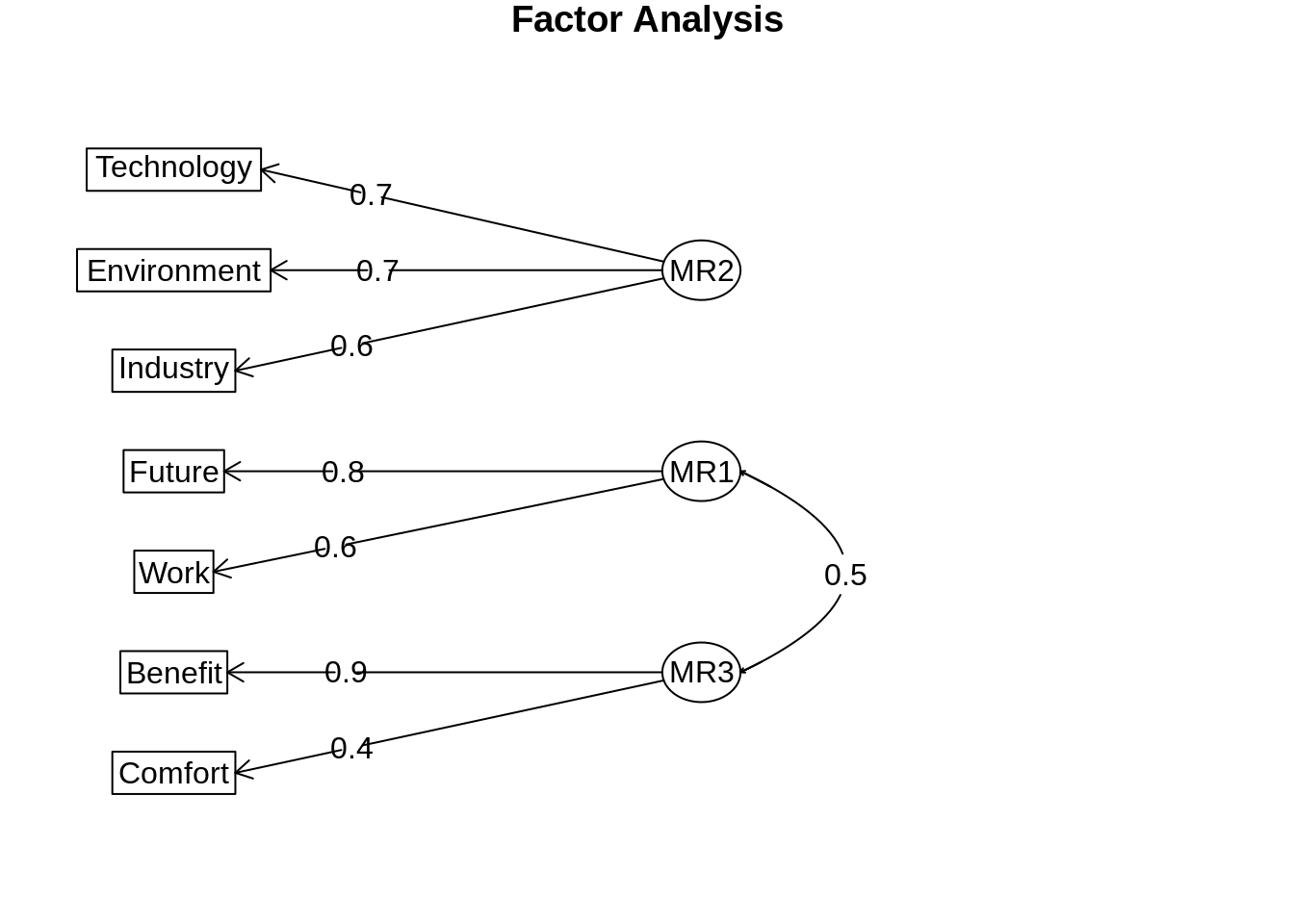
Dónde vemos que MR2 es un factor que tendrá valores altos para todos aqueellos que hayan puntuado alto en las preguntas de su grado de acuerdo con las frases.
- Technology: New technology does not depend on basic scientific research.
- Industry: Scientific and technological research do not play an important role in industrial development.
- Environment: Scientific and technological research cannot play an important role in protecting the environment and repairing it.
Es decir, los valores altos en ese factor (MR2) los tendrán aquellos que están de acuerdo con las frases anteriores, básicamente aquellos que piensan que la tecnología no depende de la investigación básica ni que esta juega un rol importante en la industria o en la protección del medio ambiente.
Dicho esto, voy a realizar un análisis parecido, pero utilizando otro tipo de técnica como es la del análisis de correspondencias. Para ver los fundamentos matemáticos del análisis de correspondencias simple aconsejo el libro de Daniel Peña Análisis Multivariante o este post de DisplayR.
En R tenemos varios paquetes para hacer análisis de correspondencias simples y múltiples, entre ellos destacan, a mi entender, ade4, FactoMineR, homals o Gifi (evolución de homals).
Para estos mismos datos voy a usar el análisis de correspondencias múltiples y la librería FactoMineR.
Nota: En el análisis de correspondencias simple, las matrices que diagonalizan son dos matrices derivadas de la tabla de contingencia entre dos variables categóricas, o más bien, la descomposición del estadístico de la distancia chi-cuadrado entre ambas en cada celda. El análisis de correspondencias múltiples es una generalización del simple para el caso de más variables categóricas.
Vamos al ejemplo
library(FactoMineR)
library(factoextra)## Loading required package: ggplot2##
## Attaching package: 'ggplot2'## The following objects are masked from 'package:psych':
##
## %+%, alpha## Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBares_mca <- MCA(datos, ncp = 3, graph = FALSE)
summary(res_mca)##
## Call:
## MCA(X = datos, ncp = 3, graph = FALSE)
##
##
## Eigenvalues
## Dim.1 Dim.2 Dim.3 Dim.4 Dim.5 Dim.6 Dim.7
## Variance 0.340 0.263 0.255 0.199 0.184 0.158 0.146
## % of var. 11.338 8.767 8.487 6.630 6.137 5.280 4.870
## Cumulative % of var. 11.338 20.105 28.592 35.222 41.359 46.640 51.509
## Dim.8 Dim.9 Dim.10 Dim.11 Dim.12 Dim.13 Dim.14
## Variance 0.142 0.135 0.127 0.125 0.121 0.112 0.105
## % of var. 4.742 4.516 4.232 4.158 4.043 3.737 3.503
## Cumulative % of var. 56.251 60.767 65.000 69.158 73.201 76.938 80.441
## Dim.15 Dim.16 Dim.17 Dim.18 Dim.19 Dim.20 Dim.21
## Variance 0.101 0.095 0.093 0.082 0.078 0.073 0.065
## % of var. 3.353 3.168 3.089 2.742 2.596 2.429 2.182
## Cumulative % of var. 83.794 86.962 90.051 92.793 95.390 97.818 100.000
##
## Individuals (the 10 first)
## Dim.1 ctr cos2 Dim.2 ctr cos2
## 1 | 0.483 0.175 0.087 | -0.109 0.012 0.004 |
## 2 | -0.340 0.087 0.100 | -0.133 0.017 0.015 |
## 3 | -0.187 0.026 0.015 | 0.345 0.115 0.053 |
## 4 | -0.183 0.025 0.017 | 0.327 0.104 0.053 |
## 5 | 0.668 0.335 0.070 | 0.111 0.012 0.002 |
## 6 | 0.341 0.087 0.051 | -0.418 0.170 0.076 |
## 7 | 0.178 0.024 0.015 | 0.071 0.005 0.002 |
## 8 | -0.068 0.003 0.002 | -0.160 0.025 0.012 |
## 9 | 0.234 0.041 0.030 | 0.059 0.003 0.002 |
## 10 | -0.328 0.081 0.071 | -0.474 0.218 0.147 |
## Dim.3 ctr cos2
## 1 -0.299 0.090 0.033 |
## 2 -0.335 0.113 0.097 |
## 3 -0.375 0.141 0.062 |
## 4 -0.460 0.212 0.104 |
## 5 1.420 2.021 0.318 |
## 6 -0.068 0.005 0.002 |
## 7 -0.349 0.122 0.056 |
## 8 -0.139 0.019 0.009 |
## 9 -0.445 0.199 0.110 |
## 10 -0.105 0.011 0.007 |
##
## Categories (the 10 first)
## Dim.1 ctr cos2 v.test Dim.2 ctr
## Comfort_strongly disagree | 0.562 0.169 0.004 1.264 | 4.427 13.579
## Comfort_disagree | -0.244 0.205 0.005 -1.441 | 0.415 0.763
## Comfort_agree | -0.276 2.170 0.161 -7.927 | 0.032 0.037
## Comfort_strongly agree | 0.881 7.400 0.228 9.440 | -0.492 2.991
## Environment_strongly disagree | 1.147 4.085 0.105 6.409 | -0.609 1.488
## Environment_disagree | -0.494 2.357 0.073 -5.337 | -0.150 0.282
## Environment_agree | -0.480 3.573 0.135 -7.265 | -0.214 0.919
## Environment_strongly agree | 0.631 5.462 0.193 8.689 | 0.486 4.188
## Work_strongly disagree | 0.276 0.270 0.007 1.656 | 1.687 13.014
## Work_disagree | -0.534 2.989 0.095 -6.091 | 0.018 0.005
## cos2 v.test Dim.3 ctr cos2 v.test
## Comfort_strongly disagree 0.253 9.951 | 3.508 8.806 0.159 7.884 |
## Comfort_disagree 0.015 2.445 | 1.047 5.022 0.097 6.173 |
## Comfort_agree 0.002 0.910 | -0.155 0.916 0.051 -4.456 |
## Comfort_strongly agree 0.071 -5.277 | -0.110 0.154 0.004 -1.179 |
## Environment_strongly disagree 0.030 -3.402 | 1.727 12.385 0.238 9.654 |
## Environment_disagree 0.007 -1.623 | 0.358 1.656 0.038 3.870 |
## Environment_agree 0.027 -3.241 | 0.059 0.072 0.002 0.892 |
## Environment_strongly agree 0.114 6.690 | -0.710 9.238 0.244 -9.777 |
## Work_strongly disagree 0.262 10.114 | 0.174 0.144 0.003 1.045 |
## Work_disagree 0.000 0.211 | -0.061 0.052 0.001 -0.695 |
##
## Categorical variables (eta2)
## Dim.1 Dim.2 Dim.3
## Comfort | 0.237 0.320 0.266 |
## Environment | 0.368 0.127 0.416 |
## Work | 0.330 0.298 0.083 |
## Future | 0.395 0.403 0.139 |
## Technology | 0.297 0.193 0.465 |
## Industry | 0.410 0.139 0.273 |
## Benefit | 0.343 0.361 0.140 |Y en el summary se ve la varianza explicada de cada dimensión y también la coordenada en cada dimensión para cada categoría de cada variable categóricas, así como su contribución a la construcción de la dimensión y su coseno al cuadrado (correlación de esa categoría con la dimensión).
Llama la atención que este análisis sugiere un mayor número de dimensiones que el obtenido utilizando las correlaciones policóricas, esto es así porque en las policóricas se supone que hay una variable latente continua y que la observada es ordinal. En un MCA no hay tal restricción y no se impone un orden a las categorías de cada variable.
En realidad, un correspondencias es equivalente en su objetivo a hacer un embedding utilizando deep learning, de hecho en este artículo Wor2vec is a special case of kernel correspondence analysis se habla de la relación entre ambas técnicas. La diferencia, para mi, es que el correspondencias parte de la geometría y del álgebra lineal y los embedding buscan optimizar una función mediante otros métodos, pero en esencia, es lo mismo.
Veamos los eigen values y la varianza explicada por cada dimensión
fviz_screeplot(res_mca, addlabels = TRUE)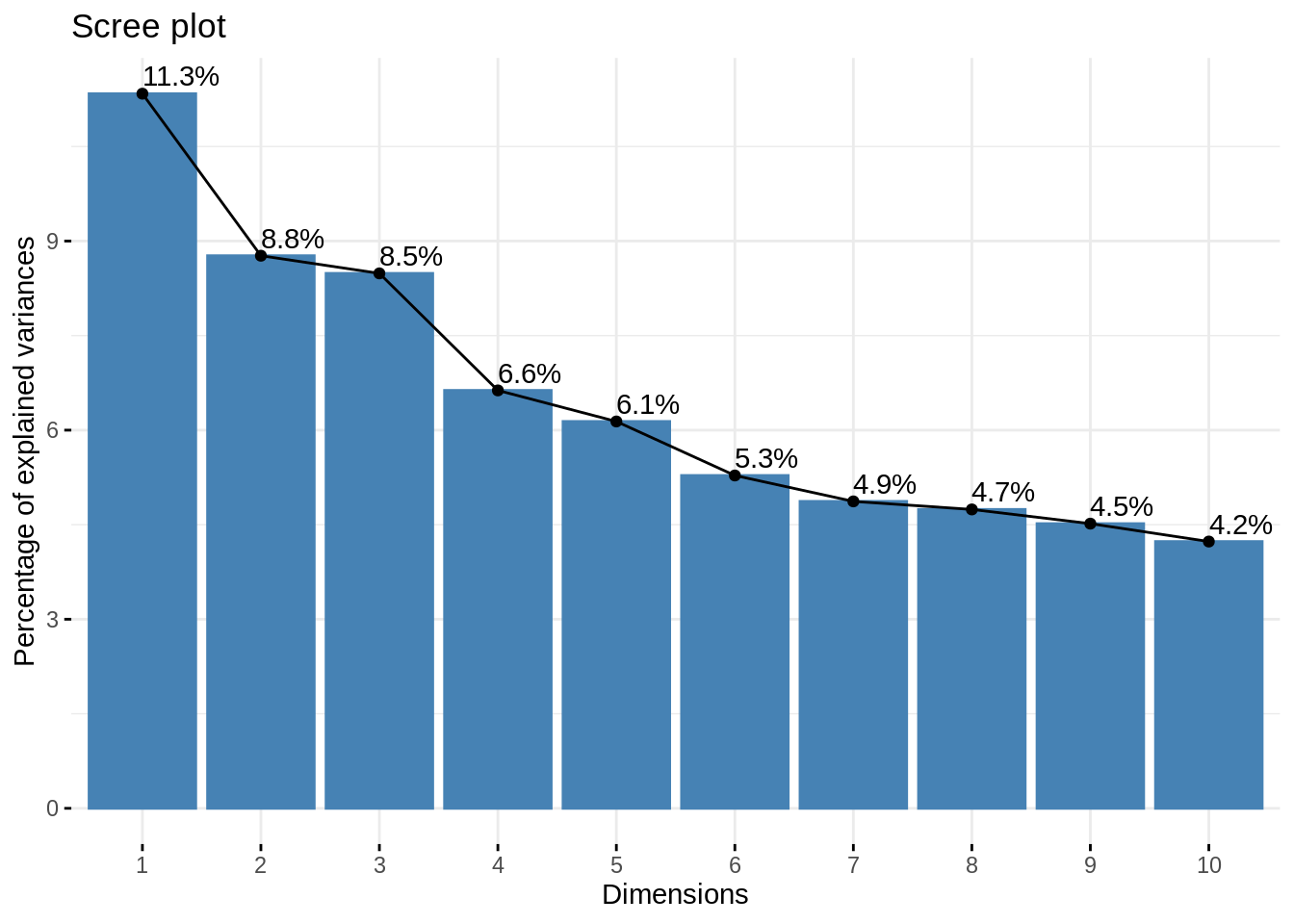
La proyección de las categorías en el plano de la dos primeras dimensions
fviz_mca_var(res_mca)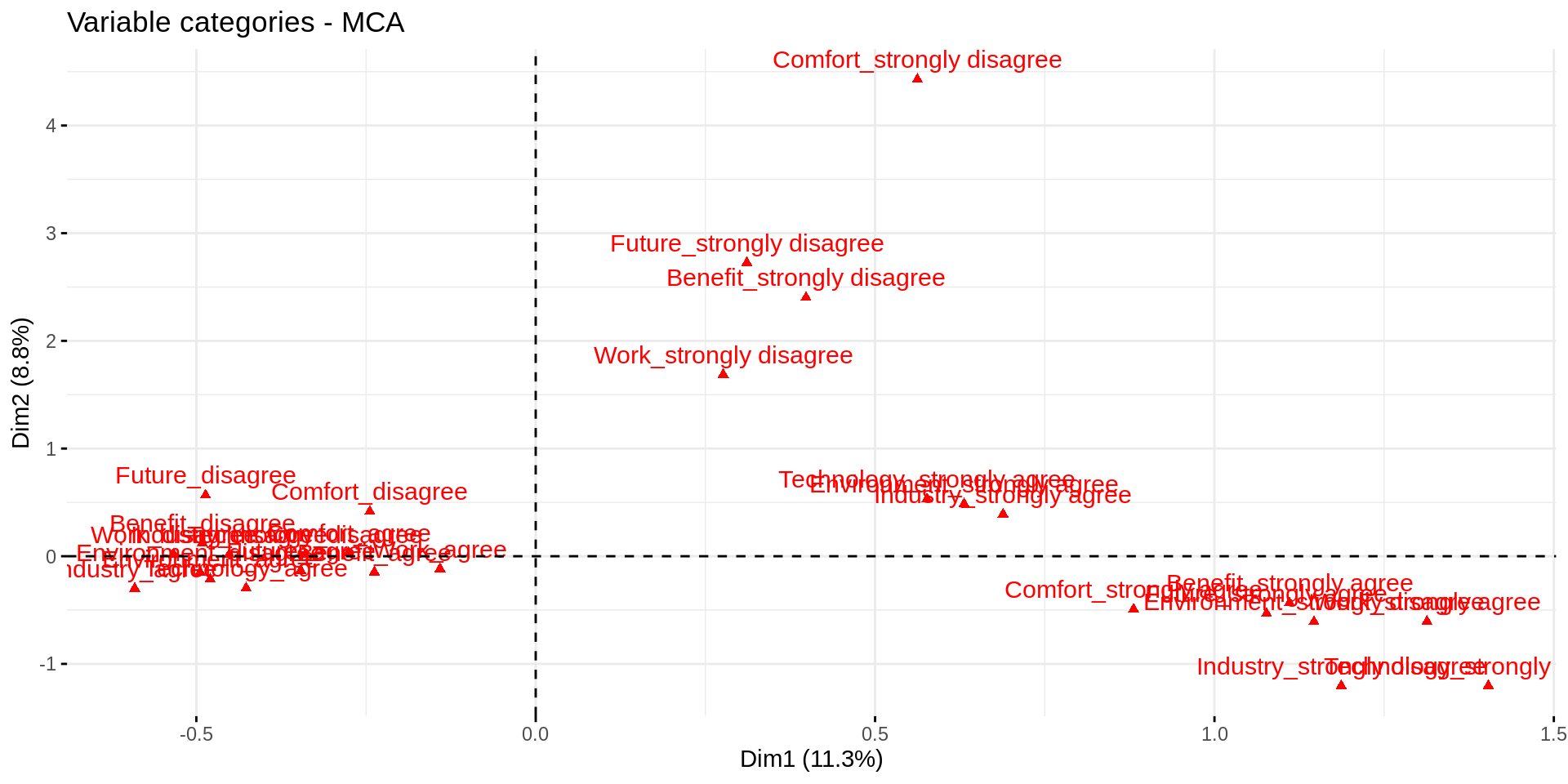
Podemos restringir el gráfico para ver solo las que más contribuyen a la formación de los ejes
fviz_mca_var(res_mca, select.var = list(contrib = 15), repel = TRUE, col.var = "cos2")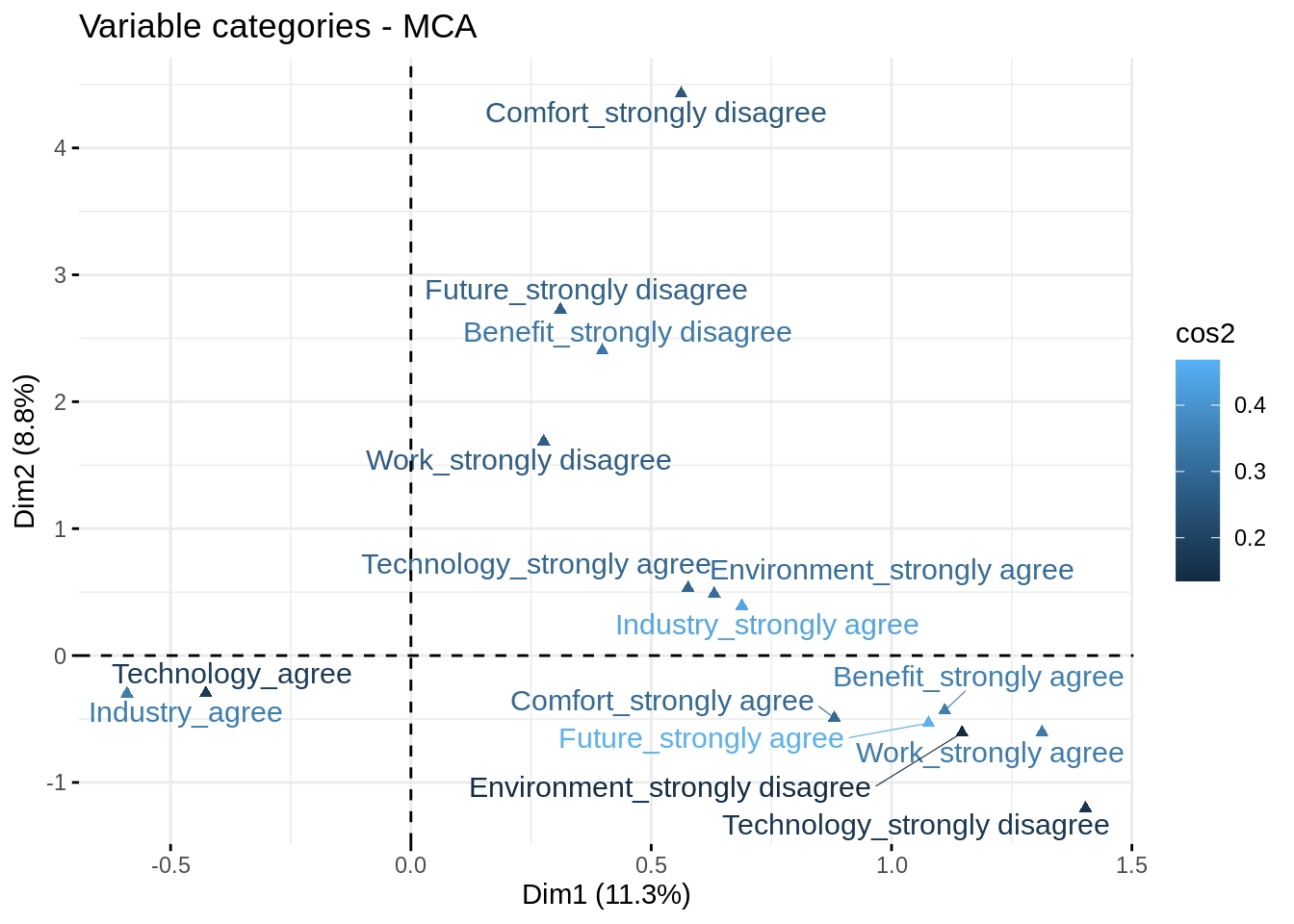
O ver el eje 1 y 3
fviz_mca_var(res_mca, select.var = list(contrib = 15), repel = TRUE, col.var = "cos2", axes = c(1,3))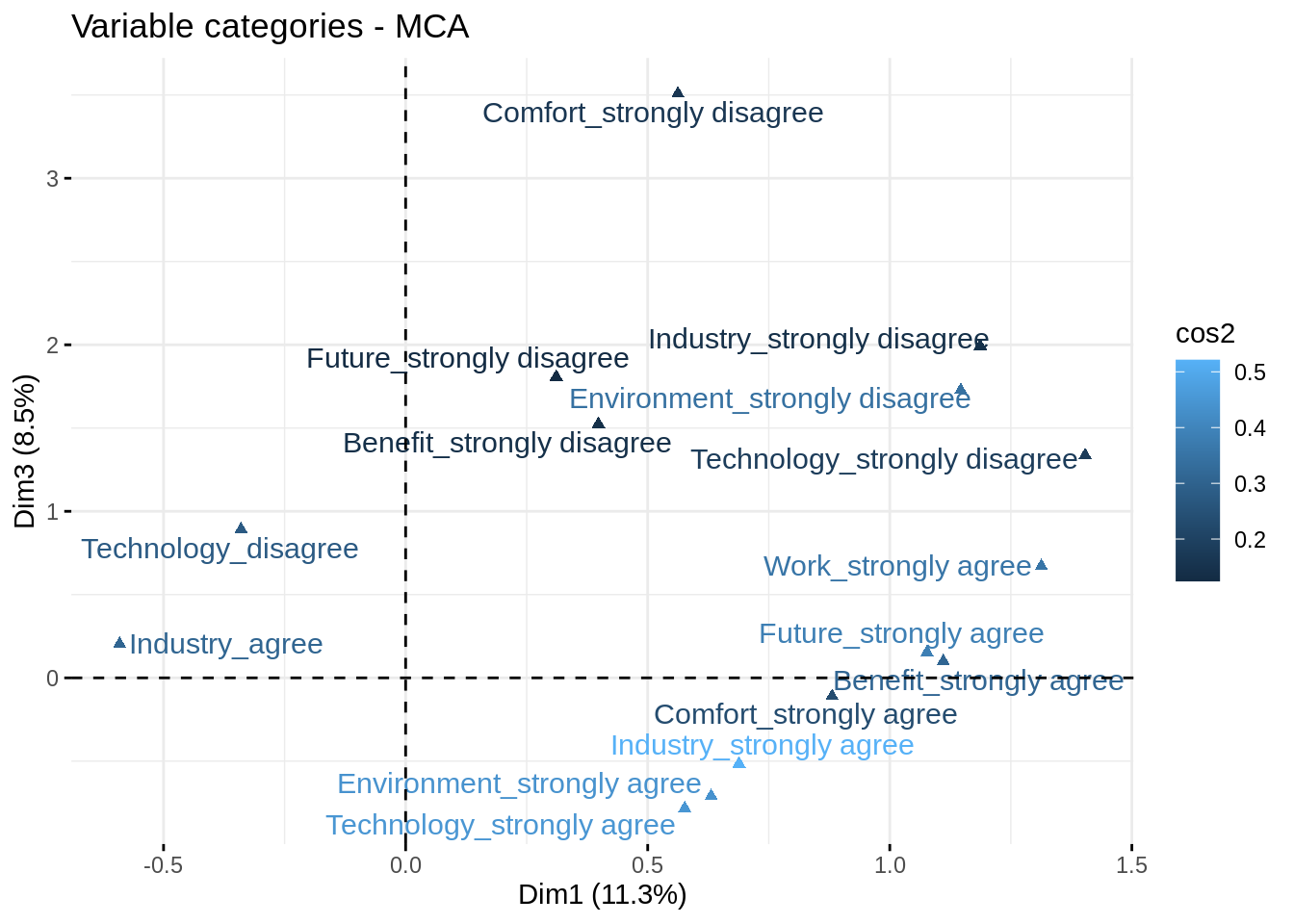
Podemos ver la puntuación (coordenadas) en cada dimensión de las diferentes categorías.
res_mca$var$coord## Dim 1 Dim 2 Dim 3
## Comfort_strongly disagree 0.5623784 4.42726189 3.50780228
## Comfort_disagree -0.2444044 0.41470372 1.04711287
## Comfort_agree -0.2759061 0.03165967 -0.15508195
## Comfort_strongly agree 0.8808997 -0.49245280 -0.11005421
## Environment_strongly disagree 1.1466586 -0.60861169 1.72734992
## Environment_disagree -0.4943875 -0.15036817 0.35848805
## Environment_agree -0.4795536 -0.21388900 0.05886528
## Environment_strongly agree 0.6310707 0.48591235 -0.71009795
## Work_strongly disagree 0.2762867 1.68706464 0.17431875
## Work_disagree -0.5335161 0.01845451 -0.06088719
## Work_agree -0.1410355 -0.11719187 -0.17811768
## Work_strongly agree 1.3130988 -0.60618454 0.67103031
## Future_strongly disagree 0.3111031 2.72537046 1.80772273
## Future_disagree -0.4864430 0.56666095 -0.04191140
## Future_agree -0.3462092 -0.13249477 -0.17587521
## Future_strongly agree 1.0767958 -0.53261327 0.15253435
## Technology_strongly disagree 1.4035683 -1.20381852 1.33623702
## Technology_disagree -0.3398842 0.01382260 0.89185166
## Technology_agree -0.4265843 -0.29654364 -0.04140482
## Technology_strongly agree 0.5764998 0.53149388 -0.78341438
## Industry_strongly disagree 1.1867685 -1.20381978 1.99283440
## Industry_disagree -0.4514353 0.01762165 0.60259334
## Industry_agree -0.5908065 -0.29993848 0.20380278
## Industry_strongly agree 0.6886376 0.38950208 -0.51548217
## Benefit_strongly disagree 0.3982240 2.40189240 1.52439647
## Benefit_disagree -0.4912166 0.12108848 -0.15206695
## Benefit_agree -0.2376545 -0.14896003 -0.12723657
## Benefit_strongly agree 1.1105932 -0.43332439 0.09937214Y también las puntuaciones de los individuos.
head(res_mca$ind$coord)## Dim 1 Dim 2 Dim 3
## 1 0.4833677 -0.1093546 -0.29916410
## 2 -0.3397756 -0.1330266 -0.33521517
## 3 -0.1868401 0.3449765 -0.37528042
## 4 -0.1832065 0.3272823 -0.46010907
## 5 0.6682663 0.1114301 1.42008790
## 6 0.3411250 -0.4181198 -0.06799293A los individuos con mismos valores en las variables categóricas les ha asignado las mismas “puntuaciones” factoriales. Con esos valores ya podríamos hacer por ejemplo un clustering o utilizarlos en otros procedimiento.
Otras funciones útiles de las librerías FactoMineR y factoextra son dimdesc o fviz_contrib que nos ayudan a interpretar las dimensiones obtenidas.
Por ejemplo, vemos qué variables categóricas están bien representadas en la Dimensión 1, que son Industry y Future y también la estimación de la correlación de cada categoria con la dimensión.
descripcion_dimensiones <- dimdesc(res_mca)
descripcion_dimensiones$`Dim 1`## $quali
## R2 p.value
## Industry 0.4103890 3.126865e-44
## Future 0.3950864 4.423335e-42
## Environment 0.3684938 1.801183e-38
## Benefit 0.3432825 3.456095e-35
## Work 0.3299587 1.668679e-33
## Technology 0.2969867 1.766435e-29
## Comfort 0.2367460 1.335614e-22
##
## $category
## Estimate p.value
## Future=Future_strongly agree 0.5470424 7.427185e-42
## Industry=Industry_strongly agree 0.2801432 2.614370e-36
## Benefit=Benefit_strongly agree 0.5339916 7.550519e-33
## Work=Work_strongly agree 0.6324280 7.823862e-30
## Comfort=Comfort_strongly agree 0.3791790 1.039144e-23
## Environment=Environment_strongly agree 0.2508527 6.159165e-20
## Technology=Technology_strongly agree 0.1592748 3.126262e-16
## Environment=Environment_strongly disagree 0.5515491 4.876039e-11
## Technology=Technology_strongly disagree 0.6416300 4.695274e-10
## Industry=Industry_strongly disagree 0.5706585 1.306617e-04
## Work=Work_agree -0.2156386 3.223266e-03
## Industry=Industry_disagree -0.3847595 9.276062e-04
## Technology=Technology_disagree -0.3751702 1.983562e-04
## Future=Future_disagree -0.3646552 3.906933e-06
## Benefit=Benefit_agree -0.2523209 2.809725e-06
## Environment=Environment_disagree -0.4055266 5.714611e-08
## Benefit=Benefit_disagree -0.4002010 6.788135e-09
## Work=Work_disagree -0.4445375 4.626638e-10
## Technology=Technology_agree -0.4257346 1.198196e-12
## Environment=Environment_agree -0.3968753 5.648237e-14
## Future=Future_agree -0.2828694 2.651003e-14
## Comfort=Comfort_agree -0.2954825 1.447770e-16
## Industry=Industry_agree -0.4660423 3.655848e-29
##
## attr(,"class")
## [1] "condes" "list "También se puede ver qué categorías contribuyen y en qué grado a la formación de las dimensiones. que es lo que nos ayuda a darle sentido a la dimensión. Así vemos que categorías asociadas a Work, Future o Benefit son las que más contribuyen.
res_mca$var$contrib## Dim 1 Dim 2 Dim 3
## Comfort_strongly disagree 0.1694307 13.579362286 8.80618396
## Comfort_disagree 0.2048013 0.762543769 5.02209024
## Comfort_agree 2.1695475 0.036943093 0.91569675
## Comfort_strongly agree 7.3995928 2.990598986 0.15429466
## Environment_strongly disagree 4.0853679 1.488392686 12.38529015
## Environment_disagree 2.3569067 0.281963769 1.65553901
## Environment_agree 3.5727881 0.919144653 0.07191740
## Environment_strongly agree 5.4617388 4.187596074 9.23834185
## Work_strongly disagree 0.2698975 13.014165678 0.14353231
## Work_disagree 2.9887261 0.004624555 0.05200265
## Work_agree 0.4390247 0.392013599 0.93546771
## Work_strongly agree 10.1606711 2.800343763 3.54482257
## Future_strongly disagree 0.1451783 14.408476735 6.54846046
## Future_disagree 1.8254138 3.203450433 0.01810274
## Future_agree 2.6968794 0.510805643 0.92977123
## Future_strongly agree 11.9262203 3.773411256 0.31970841
## Technology_strongly disagree 3.7993081 3.614377349 4.60030938
## Technology_disagree 1.1263366 0.002409129 10.36034419
## Technology_agree 3.0610777 1.913003800 0.03852556
## Technology_strongly agree 4.4867691 4.931806375 11.06881575
## Industry_strongly disagree 1.5090266 2.007991613 5.68446973
## Industry_disagree 1.0262513 0.002022227 2.44283454
## Industry_agree 6.4699589 2.156499765 1.02852260
## Industry_strongly agree 8.2311670 3.405442277 6.16154816
## Benefit_strongly disagree 0.3568117 16.786700243 6.98494032
## Benefit_disagree 2.5853002 0.203162980 0.33099179
## Benefit_agree 1.1679231 0.593383885 0.44722774
## Benefit_strongly agree 10.3078846 2.029363376 0.11024817Gráficamente.
fviz_contrib(res_mca, choice = "var")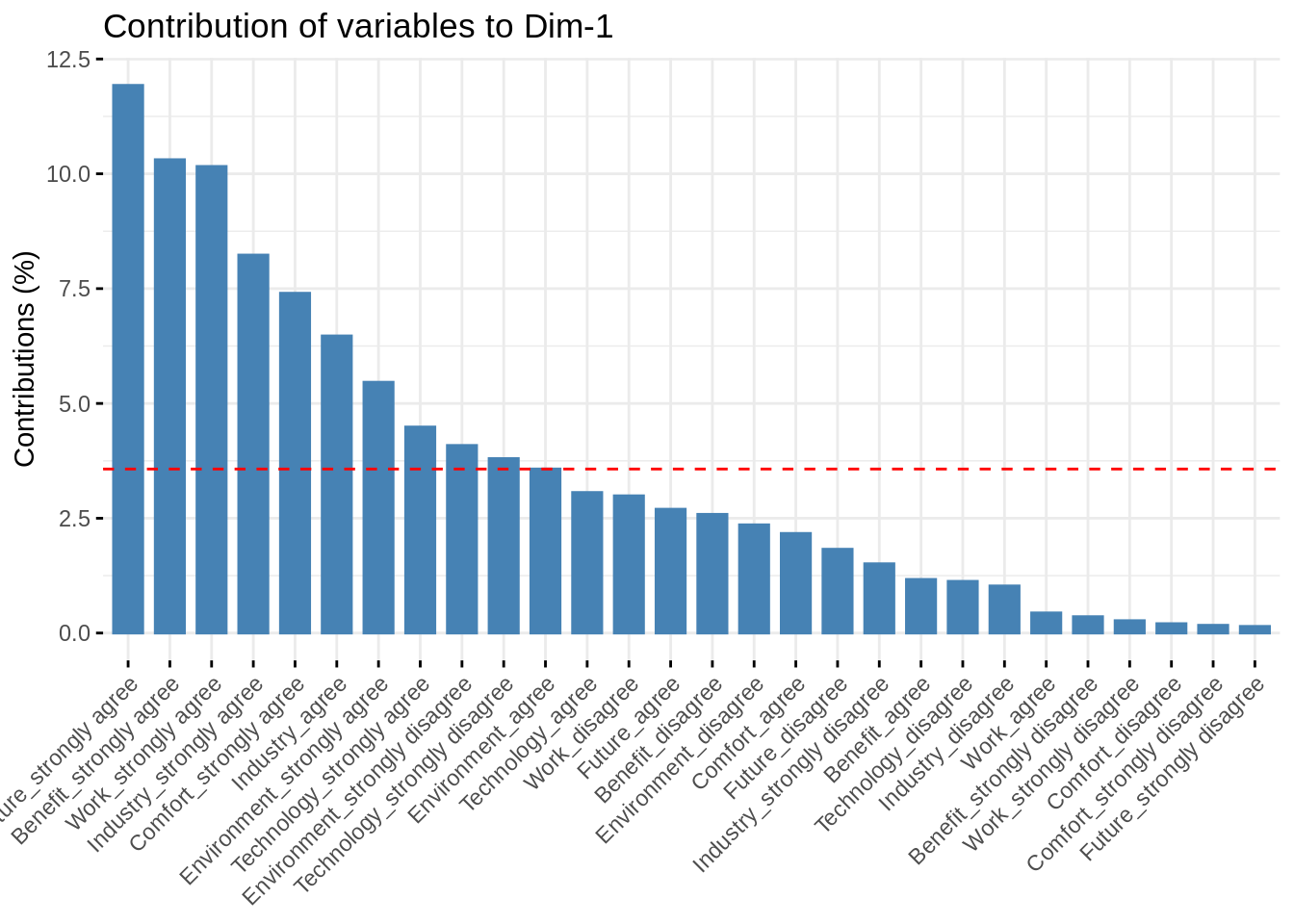 Claramente la dimensión 1 viene definida por quienes contestan strongly agree en Future, Benefit, work, Industry o comfort.
Claramente la dimensión 1 viene definida por quienes contestan strongly agree en Future, Benefit, work, Industry o comfort.
Para interpretar hay que irse a las coordenadas y ver dónde se sitúan estas categorías.
Future: Strongly agree tiene un valor alto positivo, al igual que Benefit: Strongly agree o Work: Strongly agree.
res_mca$var$coord## Dim 1 Dim 2 Dim 3
## Comfort_strongly disagree 0.5623784 4.42726189 3.50780228
## Comfort_disagree -0.2444044 0.41470372 1.04711287
## Comfort_agree -0.2759061 0.03165967 -0.15508195
## Comfort_strongly agree 0.8808997 -0.49245280 -0.11005421
## Environment_strongly disagree 1.1466586 -0.60861169 1.72734992
## Environment_disagree -0.4943875 -0.15036817 0.35848805
## Environment_agree -0.4795536 -0.21388900 0.05886528
## Environment_strongly agree 0.6310707 0.48591235 -0.71009795
## Work_strongly disagree 0.2762867 1.68706464 0.17431875
## Work_disagree -0.5335161 0.01845451 -0.06088719
## Work_agree -0.1410355 -0.11719187 -0.17811768
## Work_strongly agree 1.3130988 -0.60618454 0.67103031
## Future_strongly disagree 0.3111031 2.72537046 1.80772273
## Future_disagree -0.4864430 0.56666095 -0.04191140
## Future_agree -0.3462092 -0.13249477 -0.17587521
## Future_strongly agree 1.0767958 -0.53261327 0.15253435
## Technology_strongly disagree 1.4035683 -1.20381852 1.33623702
## Technology_disagree -0.3398842 0.01382260 0.89185166
## Technology_agree -0.4265843 -0.29654364 -0.04140482
## Technology_strongly agree 0.5764998 0.53149388 -0.78341438
## Industry_strongly disagree 1.1867685 -1.20381978 1.99283440
## Industry_disagree -0.4514353 0.01762165 0.60259334
## Industry_agree -0.5908065 -0.29993848 0.20380278
## Industry_strongly agree 0.6886376 0.38950208 -0.51548217
## Benefit_strongly disagree 0.3982240 2.40189240 1.52439647
## Benefit_disagree -0.4912166 0.12108848 -0.15206695
## Benefit_agree -0.2376545 -0.14896003 -0.12723657
## Benefit_strongly agree 1.1105932 -0.43332439 0.09937214Recordemos las frases sobre las que se preguntaba.
Comfort: Science and technology are making our lives healthier, easier and more comfortable.
Environment: Scientific and technological research cannot play an important role in protecting the environment and repairing it.
Work: The application of science and new technology will make work more interesting.
Future: Thanks to science and technology, there will be more opportunities for the future generations.
Technology: New technology does not depend on basic scientific research.
Industry: Scientific and technological research do not play an important role in industrial development.
Benefit: The benefits of science are greater than any harmful effect it may have.
Luego la dimension 1 nos va a separar a la gente que está muy de acuerdo con las frases de Future, Benefit o Work frente a los que no.
El resto de dimensiones se interpretaría de la misma forma, viendo qué categorías contribuyen a la formación de la dimensión y qué coordenadas tienen (positivos y negativos) y contra qué categorías se contraponen.
Cabría preguntarse si estas dimensiones tienen alguna relación con las calculadas en el post anterior mediante correlaciones policóricas y análisis factorial.
science.num <- data.frame(sapply(datos, as.numeric))Relación entre FA policóricas y MCA
puntuaciones <- factor.scores(science.num, res_factorial)
dimensiones_factorial <- puntuaciones$scores
dimensiones_mca <- res_mca$ind$coord
df_dimensiones <- cbind(dimensiones_factorial, dimensiones_mca)
round(cor(df_dimensiones),2)## MR2 MR1 MR3 Dim 1 Dim 2 Dim 3
## MR2 1.00 -0.01 0.07 0.31 0.38 -0.82
## MR1 -0.01 1.00 0.51 0.52 -0.66 -0.09
## MR3 0.07 0.51 1.00 0.45 -0.54 -0.19
## Dim 1 0.31 0.52 0.45 1.00 0.00 0.00
## Dim 2 0.38 -0.66 -0.54 0.00 1.00 0.00
## Dim 3 -0.82 -0.09 -0.19 0.00 0.00 1.00Y existe cierta relación, pero no tanta como se podría esperar. La dimensión 3 del MCA tiene una correlación de -0.8 con la MR2 del análisis factorial, y la Dimensión 2 ua correlación de -0.7 con la MR1 del factorial.
Nótese factorial se permitía que los factores no fueran ortogonales mientras que en MCA si lo son.
Y bueno, usando las correlaciones policóricas asumimos que existen variables latentes continuas, mientras que con un CA o un MCA se consideran las tablas de contigencia y la distancia chi-cuadrado. El supuesto subyacente es ver cuánto se aleja el valor de cada distancia chi-cuadrado en cada celda respecto del valor esperado bajo la hipótesis de independencia de las variables.
El próximo día veremos otra forma de hacer el MCA y el PCA con ordinales bajo el prisma de los Gifi Methods.