Supongo que los muchos o pocos que me leen habrán escuchado hablar del análisis factorial, o al menos de del PCA, ¿verdad? ¿Pero cuántos conocen la diferencia entre un PCA y un análisis factorial? ¿Y la relación entre un análisis de correspondencias y un PCA? ¿Y los Confirmatory Factorial Analysis (CFA)?
Hoy sólo voy a hablar un poco del diferente enfoque entre PCA y Análisis Factorial, ambos forman parte de lo que toda la vida se había llamado técnicas de interdependencia (aprendizaje no supervisado lo llaman los modernos).
El famoso PCA intenta analizar la varianza total de los datos y obtener las combinaciones lineales mejores en el sentido de máxima varianza. La primera combinación recoge el máximo de varianza, la segunda combinación se construye ortogonalmente (independiente) a la primera e intenta recoger la máxima varianza no recogida por la primera y así hasta llegar a tantas componentes como variables, de forma que al final se tiene toda la varianza. Es criterio del investigador quedarse con \(k<n\) componentes. En esencia, la primera combinación es el mejor resumen de los datos (en el sentido de recoger la máxima varianza) y la segunda el segundo mejor resumen
\[ \begin{eqnarray} F1 = a_{11}*X1 +\ldots + a_{1n}X_n \\ F2 = a_{21}*X1 +\ldots + a_{2n}X_n \end{eqnarray}\]
En cambion en el Análisis Factorial se asume que cada variable de mis datos tiene una parte común con el resto y una parte propia y se trata de obtener los factores comunes
\[ \begin{eqnarray} X1 = b_{11}*F1 +\ldots + a_{1n}F_n + U_1\\ X2 = b_{21}*F1 +\ldots + b_{2n}F_n + U_2 \end{eqnarray}\]
Visto esto, la principal diferencia es que el primero es un modelo descriptivo, mientras que el segundo se parece más a un modelo estructural o de medida.
En el segundo caso se habla de comunalidad, KMO o de rotaciones no ortogonales, se permite la correlación entre diferentes factores etcétera. Una introducción muy buena a todo este tipo de técnicas (provenientes muchas veces de la psicología) es ver la ayuda del paquete psych de R. Aquí y ver las viñetas del paquete, unas auteńticas joyas.
Os dejo un par de cosas que salen en la viñeta, analizando el famoso conjunto de datos de Thurstone (1933)
library(psych)f3w <- fa(Thurstone,3,n.obs = 213,fm="wls")## Loading required namespace: GPArotationf3w## Factor Analysis using method = wls
## Call: fa(r = Thurstone, nfactors = 3, n.obs = 213, fm = "wls")
## Standardized loadings (pattern matrix) based upon correlation matrix
## WLS1 WLS2 WLS3 h2 u2 com
## Sentences 0.90 -0.03 0.04 0.82 0.18 1.0
## Vocabulary 0.89 0.07 -0.03 0.83 0.17 1.0
## Sent.Completion 0.83 0.03 0.01 0.73 0.27 1.0
## First.Letters 0.00 0.86 0.00 0.73 0.27 1.0
## Four.Letter.Words -0.02 0.74 0.11 0.63 0.37 1.0
## Suffixes 0.18 0.63 -0.08 0.50 0.50 1.2
## Letter.Series 0.03 -0.01 0.84 0.72 0.28 1.0
## Pedigrees 0.38 -0.05 0.46 0.51 0.49 2.0
## Letter.Group -0.06 0.21 0.63 0.53 0.47 1.2
##
## WLS1 WLS2 WLS3
## SS loadings 2.65 1.86 1.49
## Proportion Var 0.29 0.21 0.17
## Cumulative Var 0.29 0.50 0.67
## Proportion Explained 0.44 0.31 0.25
## Cumulative Proportion 0.44 0.75 1.00
##
## With factor correlations of
## WLS1 WLS2 WLS3
## WLS1 1.00 0.59 0.53
## WLS2 0.59 1.00 0.52
## WLS3 0.53 0.52 1.00
##
## Mean item complexity = 1.2
## Test of the hypothesis that 3 factors are sufficient.
##
## The degrees of freedom for the null model are 36 and the objective function was 5.2 with Chi Square of 1081.97
## The degrees of freedom for the model are 12 and the objective function was 0.01
##
## The root mean square of the residuals (RMSR) is 0.01
## The df corrected root mean square of the residuals is 0.01
##
## The harmonic number of observations is 213 with the empirical chi square 0.53 with prob < 1
## The total number of observations was 213 with Likelihood Chi Square = 2.89 with prob < 1
##
## Tucker Lewis Index of factoring reliability = 1.026
## RMSEA index = 0 and the 90 % confidence intervals are 0 0
## BIC = -61.45
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## WLS1 WLS2 WLS3
## Correlation of (regression) scores with factors 0.96 0.92 0.90
## Multiple R square of scores with factors 0.93 0.85 0.81
## Minimum correlation of possible factor scores 0.86 0.71 0.63Diagramas
fa.diagram(f3w)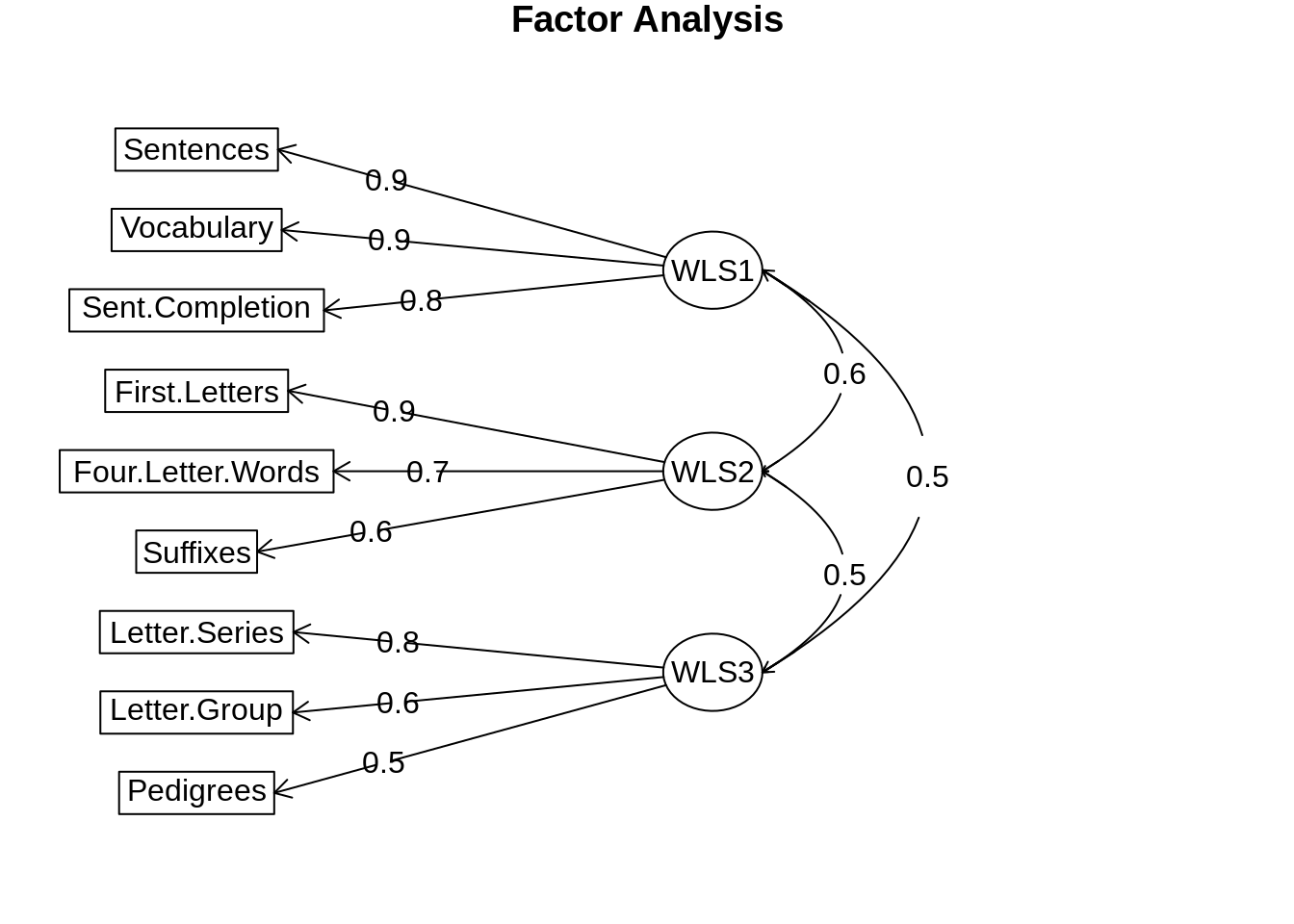
om.h <- omega(Thurstone,n.obs=213,sl=FALSE)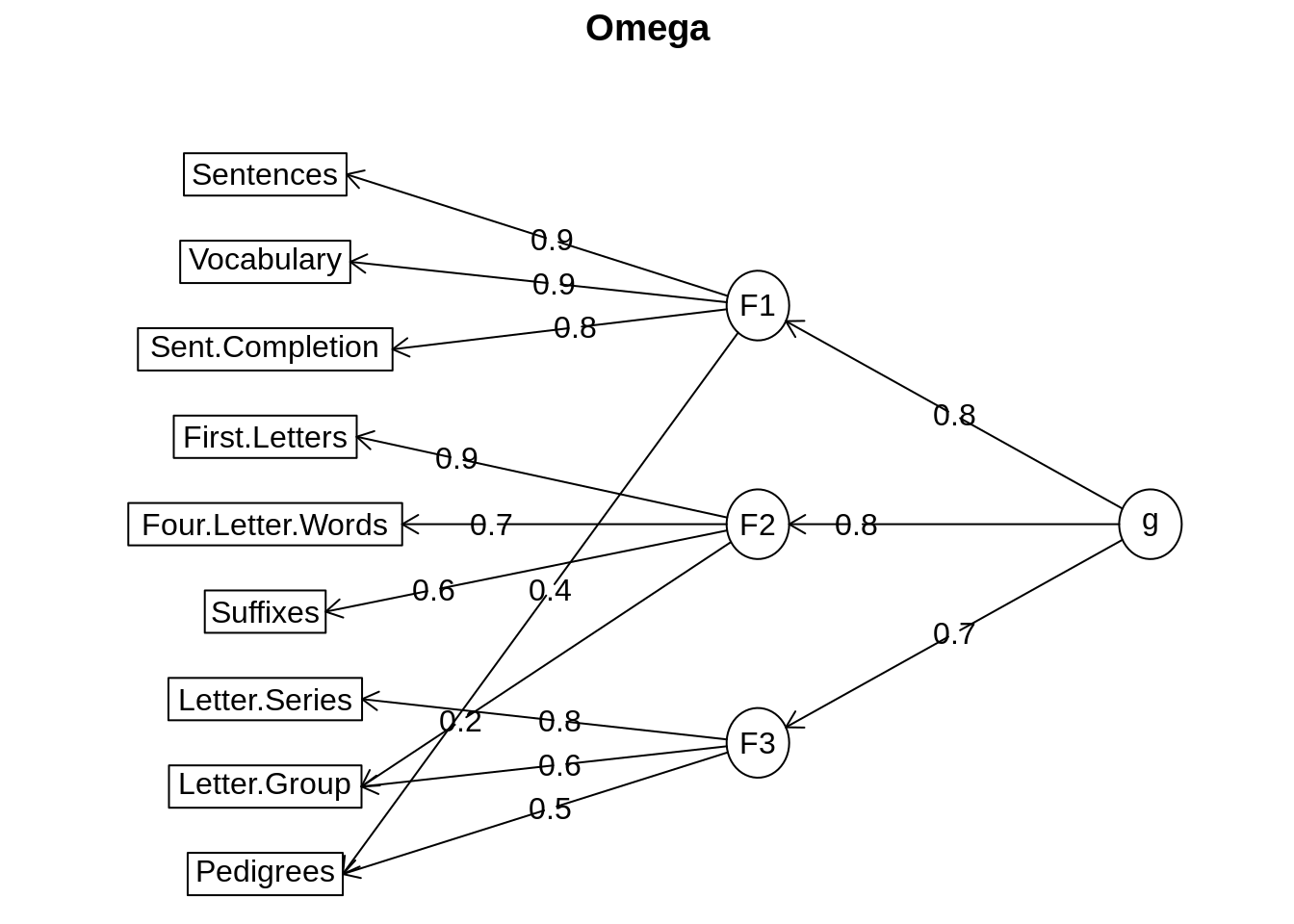
iclust(Thurstone)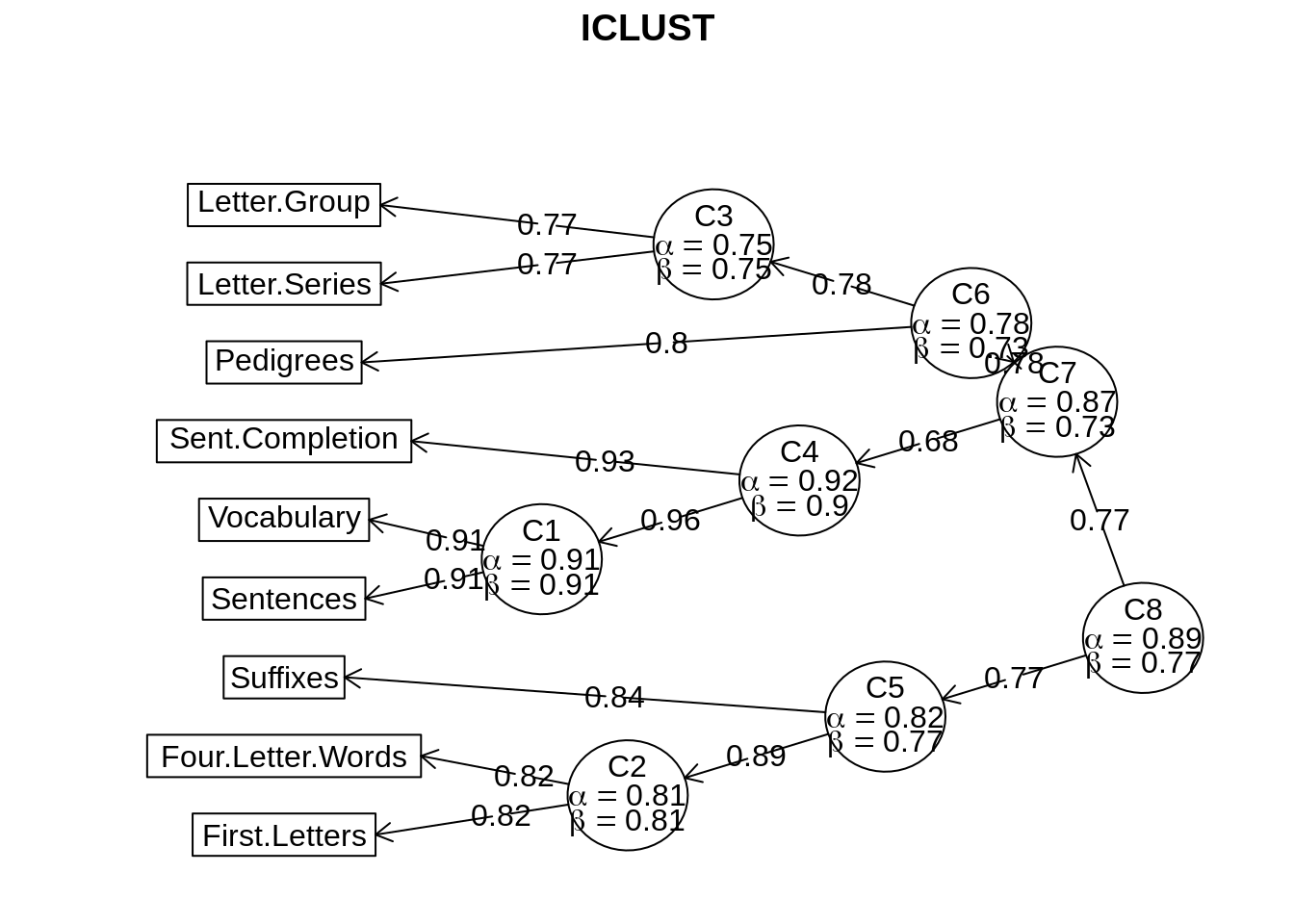
## ICLUST (Item Cluster Analysis)
## Call: iclust(r.mat = Thurstone)
##
## Purified Alpha:
## [1] 0.89
##
## G6* reliability:
## [1] 1
##
## Original Beta:
## [1] 0.77
##
## Cluster size:
## [1] 9
##
## Item by Cluster Structure matrix:
## [,1]
## Sentences 0.80
## Vocabulary 0.82
## Sent.Completion 0.77
## First.Letters 0.70
## Four.Letter.Words 0.68
## Suffixes 0.62
## Letter.Series 0.63
## Pedigrees 0.65
## Letter.Group 0.60
##
## With eigenvalues of:
## [1] 4.4
##
## Purified scale intercorrelations
## reliabilities on diagonal
## correlations corrected for attenuation above diagonal:
## [,1]
## [1,] 0.89
##
## Cluster fit = 0.88 Pattern fit = 0.97 RMSR = 0.1Otro día contaré más en profundidad como se tratan cuando las variables son ordinales o nominales (correlaciones policóricas, análisis de correspondencias, escalamiento óptimo) o algunas cosas de las que conozco menos como la teoría del respuesta al ítem. Y cómo dice un amigo mío, si no tenemos en cuenta la estructuta, palmamos pasta
comments powered by Disqus