Llevo un tiempo que me llegan noticias tales como “Con el big data predecimos cuál va a ser tu próxima tienda y cuánto te vas a gastar” o “predecimos los rebotes por partido de un jugador con un margen de error de un rebote cada 6 partidos” y cosas aún más peregrinas.
La verdad es que entre la gente más o menos seria que nos dedicamos a esto creo que está bastante claro que nuestra labor es reducir (y medir) la incertidumbre de algunos procesos de toma de decisiones, lean esto si quieren saber más en qué debería consistir nuestro trabajo.
¡No hacemos magia, no tenemos ingestado todo Internet, no sabemos si te vas a tomar esta tarde una caña con bocata de calamares o 2 vinos !
Otro amigo mío dice que el “big data son los padres”, y no le falta razón, sobre todo por el problema de gestión de expectativas, entre todos estamos vendiendo que con la Inteligencia Artificial o el deep learning vamos a hacer maravillas. En realidad todos suspiramos por unos datos limpios y por unos modelos sencillos, pero útiles.
Y otro tema es el de la cantidad de gente que quiere entrar en el sector de la analítica pidiendo 50k con 1 año de experiencia, cuándo no saben ni interpretar un coeficiente de una regresión lineal. Mejor me callo que me enervo.
Pero bueno, veamos qué tal ha ido la evolución de búsquedas en Google de ciertos términos relacionados con estos temas.
Vamos a usar la librería gtrendsR que ataca a la API de googleTrends
library(gtrendsR)
library(tidyverse)## ── Attaching packages ──────────────────────────────── tidyverse 1.2.1 ──## ✔ ggplot2 3.1.0 ✔ purrr 0.3.2
## ✔ tibble 2.1.1 ✔ dplyr 0.8.0.1
## ✔ tidyr 0.8.3 ✔ stringr 1.4.0
## ✔ readr 1.3.1 ✔ forcats 0.4.0## ── Conflicts ─────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()library(patchwork)A petición de lector del blog, compañero de trabajo y sin embargo amigo pongo las búsquedas desde más atrás, pero sólo para las globales
today <- Sys.Date()
fecha_inicio <- "2009-01-01"
intervalo <- paste(fecha_inicio, today, sep = " ")
hype_words_all <- gtrends(c("big data","machine learning","artificial intelligence","deep learning"), time = intervalo)
# hype_words_spain <- gtrends(c("big data","machine learning","artificial intelligence","deep learning"), geo="ES", time = intervalo)interest_over_time_all <- hype_words_all$interest_over_time
interest_over_time_all <- interest_over_time_all %>% filter(hits >0 & !is.na(hits))
#
# interest_over_time_spain <- hype_words_spain$interest_over_time
# interest_over_time_spain <- interest_over_time_spain %>% filter(hits >0 & !is.na(hits))p1 <- ggplot(interest_over_time_all, aes(x = date, y = hits, color=keyword)) +
geom_point(size = rel(0.5)) +
geom_smooth(span = 0.8) +
labs(title="World: Interest last ten years", y = "relative interest")
p1## `geom_smooth()` using method = 'loess' and formula 'y ~ x'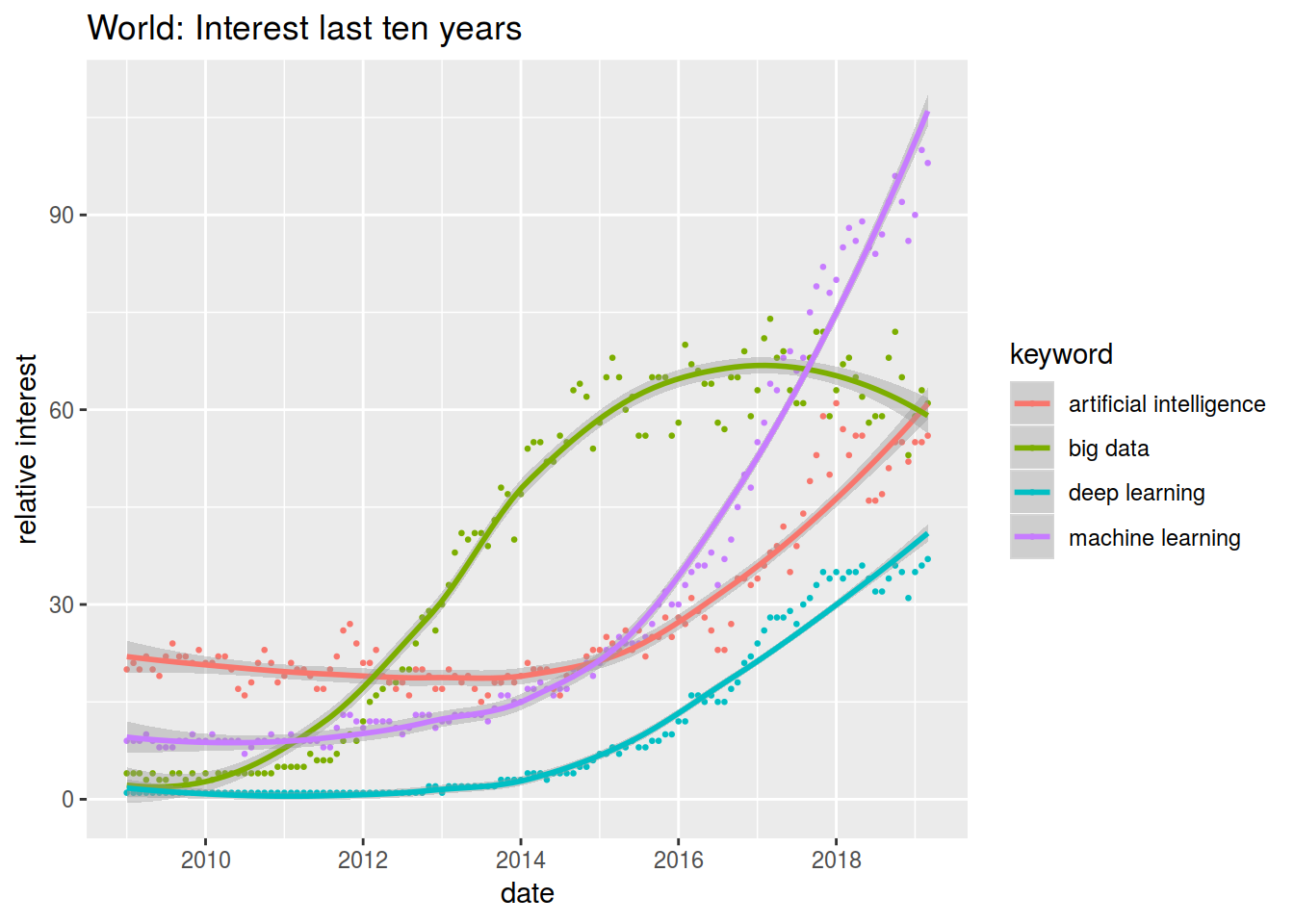
# p2 <- ggplot(interest_over_time_spain, aes(x = date, y = hits, color=keyword)) +
# geom_point(size = rel(0.5)) +
# geom_smooth() +
# labs(title="Spain: Interest last five years", y = "relative interest")
# p1 + p2 + plot_layout(ncol = 1)Pues ¿qué les parece? ¿Vamos camino de un burbuja o ya estamos en ella?
comments powered by Disqus